REPLICATION PACKAGE: The impact of dyads and extended networks on political talk: A factorial survey experiment in the Netherlands
1 Introduction
This website is a supplement to the paper The impact of dyads and extended networks on political talk: A factorial survey experiment in the Netherlands It contains the link to the publicly available data set we used NELLS and all the necessary R code to replicate our reported results and tables.
Hofstra, B., Jeroense, T., Tolsma, J. (2026). The impact of dyads and extended networks on political talk: A factorial survey experiment in the Netherlands. Social Networks, 85, 66-67 pdf doi
1.1 Contact
Questions can be addressed to Bas Hofstra
1.2 general custom functions
fpackage.check: Check if packages are installed (and install if not) in Rfsave: Function to save data with time stamp in correct directoryfload: Function to load R-objects under new namesfshowdf: Print objects (tibble/data.frame) nicely on screen in.Rmdftheme: pretty ggplot2 theme
fpackage.check <- function(packages) {
lapply(packages, FUN = function(x) {
if (!require(x, character.only = TRUE)) {
install.packages(x, dependencies = TRUE)
library(x, character.only = TRUE)
}
})
}
fsave <- function(x, location = "./data/processed/") {
if (location == "./data/processed/") {
ifelse(!dir.exists("data"), dir.create("data"), FALSE)
ifelse(!dir.exists("data/processed"), dir.create("data/processed"), FALSE)
}
object = deparse(substitute(x))
datename <- substr(gsub("[:-]", "", Sys.time()), 1, 8)
totalname <- paste(location, object, "_", datename, ".rda", sep = "")
assign(eval(object), x, envir = .GlobalEnv)
print(paste("SAVED: ", totalname, sep = ""))
save(list = object, file = totalname)
}
fload <- function(fileName) {
load(fileName)
get(ls()[ls() != "fileName"])
}
fshowdf <- function(x, caption = NULL, ...) {
knitr::kable(x, digits = 2, "html", caption = caption, ...) %>%
kableExtra::kable_styling(bootstrap_options = c("striped", "hover")) %>%
kableExtra::scroll_box(width = "100%", height = "300px")
}
ftheme <- function() {
# download font at https://fonts.google.com/specimen/Jost/
theme_minimal(base_family = "Jost") + theme(panel.grid.minor = element_blank(), plot.title = element_text(family = "Jost",
face = "bold"), axis.title = element_text(family = "Jost Medium"), axis.title.x = element_text(hjust = 0),
axis.title.y = element_text(hjust = 1), strip.text = element_text(family = "Jost", face = "bold",
size = rel(0.75), hjust = 0), strip.background = element_rect(fill = "grey90", color = NA),
legend.position = "bottom")
}1.3 necessary packages
To further ease replication purposes we use groundhog.
packages <- c("tidyverse", "lme4", "psych", "ordinal", "ggplot2", "officer", "flextable", "Hmisc", "jtools",
"parallel")
fpackage.check(packages)1.4 session info
sessionInfo()#> R version 4.4.2 (2024-10-31 ucrt)
#> Platform: x86_64-w64-mingw32/x64
#> Running under: Windows 11 x64 (build 26100)
#>
#> Matrix products: default
#>
#>
#> locale:
#> [1] LC_COLLATE=English_United Kingdom.utf8 LC_CTYPE=English_United Kingdom.utf8
#> [3] LC_MONETARY=English_United Kingdom.utf8 LC_NUMERIC=C
#> [5] LC_TIME=English_United Kingdom.utf8
#>
#> time zone: Europe/Amsterdam
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] jtools_2.3.0 Hmisc_5.1-3 flextable_0.9.6 officer_0.6.6
#> [5] ordinal_2023.12-4.1 psych_2.4.6.26 lme4_1.1-35.5 Matrix_1.7-0
#> [9] lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4
#> [13] purrr_1.0.2 readr_2.1.5 tidyr_1.3.1 tibble_3.2.1
#> [17] ggplot2_3.5.1 tidyverse_2.0.0 groundhog_3.2.1 knitr_1.48
#>
#> loaded via a namespace (and not attached):
#> [1] mnormt_2.1.1 gridExtra_2.3 formatR_1.14 rlang_1.1.4
#> [5] magrittr_2.0.3 furrr_0.3.1 compiler_4.4.2 systemfonts_1.1.0
#> [9] vctrs_0.6.5 pkgconfig_2.0.3 fastmap_1.2.0 backports_1.5.0
#> [13] pander_0.6.5 utf8_1.2.4 rmarkdown_2.28 tzdb_0.4.0
#> [17] nloptr_2.1.1 ragg_1.3.3 xfun_0.48 cachem_1.1.0
#> [21] jsonlite_1.8.9 uuid_1.2-1 broom_1.0.7 parallel_4.4.2
#> [25] cluster_2.1.6 R6_2.5.1 bslib_0.8.0 stringi_1.8.4
#> [29] parallelly_1.38.0 boot_1.3-31 extrafontdb_1.0 rpart_4.1.23
#> [33] jquerylib_0.1.4 numDeriv_2016.8-1.1 Rcpp_1.0.13 assertthat_0.2.1
#> [37] klippy_0.0.0.9500 base64enc_0.1-3 extrafont_0.19 splines_4.4.2
#> [41] nnet_7.3-19 timechange_0.3.0 tidyselect_1.2.1 rstudioapi_0.16.0
#> [45] yaml_2.3.10 codetools_0.2-20 listenv_0.9.1 lattice_0.22-6
#> [49] withr_3.0.1 askpass_1.2.1 evaluate_1.0.0 foreign_0.8-87
#> [53] future_1.34.0 zip_2.3.1 xml2_1.3.6 pillar_1.9.0
#> [57] checkmate_2.3.2 generics_0.1.3 hms_1.1.3 munsell_0.5.1
#> [61] scales_1.3.0 minqa_1.2.8 globals_0.16.3 glue_1.8.0
#> [65] gdtools_0.4.0 tools_4.4.2 data.table_1.16.0 rgl_1.3.14
#> [69] grid_4.4.2 Rttf2pt1_1.3.12 colorspace_2.1-1 nlme_3.1-166
#> [73] htmlTable_2.4.3 Formula_1.2-5 cli_3.6.3 textshaping_0.4.0
#> [77] fontBitstreamVera_0.1.1 fansi_1.0.6 gtable_0.3.5 broom.mixed_0.2.9.5
#> [81] sass_0.4.9 digest_0.6.37 fontquiver_0.2.1 ucminf_1.2.2
#> [85] htmlwidgets_1.6.4 htmltools_0.5.8.1 lifecycle_1.0.4 fontLiberation_0.1.0
#> [89] openssl_2.2.2 MASS_7.3-612 NELLS
We use the third wave of the NEtherlands Longitudinal Lifecourse Study (Jeroense et al. 2023). This dataset is publically available at DANS Data Station Social Sciences and Humanities, see https://doi.org/10.17026/DANS-XYK-M56B. Please make sure to download the dataset with the variables that were originally under embargo included.
# df <- fload('Data/2023-04-06_nells-cleaned-22-V1.0.Rdata')
df_dans <- fload("Data/nells-22_V1.1.Rdata")
df <- df_dans2.1 gender and ethnic background
df$female <- as.numeric(df$B02 == 2) #gender
# etnicity, no missings
df$egoNL <- as.numeric(df$B05 == 1 & df$B06 == 1 & df$B07 == 1)
df$egoM <- as.numeric(df$B05 == 2 | df$B06 == 2 | df$B07 == 2)
df$egoT <- as.numeric(df$B05 == 3 | df$B06 == 3 | df$B07 == 3)
df$egoM <- ifelse(df$B06 == 2, 1, df$egoM) #mother dominant
df$egoT <- ifelse(df$B06 == 3, 1, df$egoT) #mother dominant
df$egoO <- as.numeric(df$egoNL != 1 & df$egoM != 1 & df$egoT != 1) #other, need to filter
# generation
df$ego_gen1 <- as.numeric(df$B05 == 2 | df$B05 == 3)
# table(df$egoM, useNA = 'always') table(df$egoT, useNA = 'always') table(df$egoO, useNA =
# 'always') #need to filter2.2 age and education
# age table(is.na(df$cage))
# education
df$educL <- as.numeric(df$C05 < 5 | df$C05 == 13) # lower than Havo
df$educM <- as.numeric((df$C05 > 4 & df$C05 < 9) | df$C05 == 14) # have, vwo, mbo
df$educH <- as.numeric((df$C05 > 8 & df$C05 < 13) | df$C05 == 15) # hbo, wo
df$educ_current <- as.numeric(df$C03 == 1) # currently full-time in educ2.3 additional potential controls
# political opinions H12d. De overheid moet de inkomensverschillen in Nederland kleiner maken H12e.
# De topinkomens in het bedrijfsleven zijn te hoog H12f. De overheid moet de sociale uitkeringen
# verhogen attributes(df$H12e)
df$ego_opinion1 <- df$H12e
df$ego_opinion1b <- rowMeans(cbind(df$H12d, df$H12e, df$H12f), na.rm = T)
# table(df$ego_opinion1, useNA = 'always')
# H12a. Als een land spanningen wil verminderen moet de immigratie stoppen
df$ego_opinion2 <- df$H12a
# attributes(df$H12a) reverse coding
df$ego_opinion2 <- 6 - df$ego_opinion2
# H13d. Het klimaat verbeteren moet prioriteit hebben, zelfs als dit de economische groei vertraagt
df$ego_opinion3 <- df$H13d
# table(df$ego_opinion3, useNA = 'always') attributes(df$H13d)
df %>%
select(c(ego_opinion1, ego_opinion2, ego_opinion3, ego_opinion1b, H12d, H12e, H12f)) %>%
as.matrix() %>%
Hmisc::rcorr()
# feeling thermometers
df$thermoD <- df$H19i
df$thermoM <- df$H19j
df$thermoT <- df$H19k
# H06. Political interest
df$polint <- df$H06
# table(df$H06, useNA = 'always') attributes(df$H06)
# district variables: gender and ethnic diversity
df <- df %>%
mutate(cdistrict2020_a_nl = cdistrict2020_a_inw - cdistrict2020_a_w_all - cdistrict2020_a_w_all,
district_EI_ethnic = case_when(egoNL == 1 ~ (cdistrict2020_a_nl - (cdistrict2020_a_inw - cdistrict2020_a_nl))/cdistrict2020_a_inw,
egoM == 1 ~ (cdistrict2020_a_marok - (cdistrict2020_a_inw - cdistrict2020_a_marok))/cdistrict2020_a_inw,
egoT == 1 ~ (cdistrict2020_a_tur - (cdistrict2020_a_inw - cdistrict2020_a_tur))/cdistrict2020_a_inw,
.default = NA), district_EI_gender = case_when(female == 1 ~ (cdistrict2020_a_vrouw - cdistrict2020_a_man)/(cdistrict2020_a_vrouw +
cdistrict2020_a_man), female == 0 ~ (cdistrict2020_a_man - cdistrict2020_a_vrouw)/(cdistrict2020_a_vrouw +
cdistrict2020_a_man))) %>%
mutate(district_EI_ethnic = ifelse(district_EI_ethnic > 1 | district_EI_ethnic < -1, NA, district_EI_ethnic),
district_EI_gender = ifelse(district_EI_gender > 1 | district_EI_gender < -1, NA, district_EI_gender))
# Core Discussion Network (size of non-kin network, gender/ethnic EI )
df <- df %>%
mutate(across(I02a:I05e, ~replace_na(.x, -1)) #replace NA's with -1
) %>%
mutate(cdn_tot = 5 - rowSums(cbind(is.na(df$calter_id1), is.na(df$calter_id2), is.na(df$calter_id3),
is.na(df$calter_id4), is.na(df$calter_id5)))) %>%
rowwise() %>%
# to be able to count values across variables for each row
mutate(nka = !(I02a < 4 & I02a > 1), nkb = !(I02b < 4 & I02b > 1), nkc = !(I02c < 4 & I02c > 1), nkd = !(I02d <
4 & I02d > 1), nke = !(I02e < 4 & I02e > 1), cdn_tot_nk = cdn_tot - sum(c(I02a < 4 & I02a > 1, I02b <
4 & I02b > 1, I02c < 4 & I02c > 1, I02d < 4 & I02d > 1, I02e < 4 & I02e > 1)), cdn_NL = sum(c(nka &
I04a == 1, nkb & I04b == 1, nkc & I04c == 1, nkd & I04d == 1, nke & I04e == 1)), cdn_M = sum(c(nka &
I04a == 2, nkb & I04b == 2, nkc & I04c == 2, nkd & I04d == 2, nke & I04e == 2)), cdn_T = sum(c(nka &
I04a == 3, nkb & I04b == 3, nkc & I04c == 3, nkd & I04d == 3, nke & I04e == 3)), cdn_O = sum(c(nka &
I04a == 4, nkb & I04b == 4, nkc & I04c == 4, nkd & I04d == 4, nke & I04e == 4)), cdn_men = sum(c(nka &
I03a == 1, nkb & I03b == 1, nkc & I03c == 1, nkd & I03d == 1, nke & I03e == 1)), cdn_women = sum(c(nka &
I03a == 2, nkb & I03b == 2, nkc & I03c == 2, nkd & I03d == 2, nke & I03e == 2))) %>%
ungroup() %>%
# higher EI scores indicate more intragroup ties than intergroup ties. range -1 to 1, note only
# relvant if size>0
mutate(cdn_EI_ethnic = case_when(egoNL == 1 ~ (cdn_NL - (cdn_tot_nk - cdn_NL))/cdn_tot_nk, egoM == 1 ~
(cdn_M - (cdn_tot_nk - cdn_M))/cdn_tot_nk, egoT == 1 ~ (cdn_T - (cdn_tot_nk - cdn_T))/cdn_tot_nk,
.default = NA), cdn_EI_gender = case_when(female == 1 ~ (cdn_women - (cdn_tot_nk - cdn_women))/cdn_tot_nk,
female == 0 ~ (cdn_men - (cdn_tot_nk - cdn_men))/cdn_tot_nk, .default = NA)) %>%
mutate(across(c(cdn_tot:cdn_EI_gender), ~ifelse(is.na(H19o) & is.na(J01a), NA, .))) %>%
# if respondents did not answer questions, replace values with NA
mutate(cdn_EI_ethnic = ifelse(cdn_EI_ethnic > 1 | cdn_EI_ethnic < -1, NA, cdn_EI_ethnic), cdn_EI_gender = ifelse(cdn_EI_gender >
1 | cdn_EI_gender < -1, NA, cdn_EI_gender))
# few data discrepancies table(df$cdn_EI_ethnic)2.4 NSUM
For construction see here.
nsum <- fload("./Data/nsum_outcomes/nsum_size_diversity.rda")2.4.1 diversity measures
Higher scores more diversity.
nsum$hhi_ethnic <- 1 - nsum$hhi_ethnic
nsum$hhi_gender <- 1 - nsum$hhi_gender
nsum$hhi_educ <- 1 - nsum$hhi_educdf <- df %>%
left_join(y = nsum)
# calculate the EI scores
df <- df %>%
mutate(nsum_EI_ethnic = case_when(egoNL == 1 ~ (nsum_dut - (nsum_mor + nsum_tur))/(nsum_dut + nsum_mor +
nsum_tur), egoM == 1 ~ (nsum_mor - (nsum_dut + nsum_tur))/(nsum_dut + nsum_mor + nsum_tur), egoT ==
1 ~ (nsum_tur - (nsum_dut + nsum_mor))/(nsum_dut + nsum_mor + nsum_tur), .default = NA), nsum_EI_gender = case_when(female ==
1 ~ (nsum_women - (nsum_men))/(nsum_women + nsum_men), female == 0 ~ (nsum_men - (nsum_women))/(nsum_women +
nsum_men), .default = NA)) %>%
mutate(nsum_EI_ethnic = ifelse(nsum_EI_ethnic > 1 | nsum_EI_ethnic < -1, NA, nsum_EI_ethnic), nsum_EI_gender = ifelse(nsum_EI_gender >
1 | nsum_EI_gender < -1, NA, nsum_EI_gender))2.5 Sample selection and missings
As described in our manuscript, NELLS applied a split ballot design. The NSUM items were only included in split ballot 2.
table(df$csplitballot, useNA = "always")
df_sb1 <- df[df$csplitballot == 1, ] #1503
df_sb2 <- df[df$csplitballot == 2, ] #1514#>
#> 1 2 <NA>
#> 1503 1514 03 Table 1
To summarize the dimension of the survey experiment we report Table 1 in our manuscript.
Gender | Ethnic background | Relationship | Policy measure | Political distance |
|---|---|---|---|---|
1. Man | 1. Dutch | 1. a colleague | 1. introduce higher taxes for people with top incomes | 1. thinks substantively more negative about this proposal than you |
2. Woman | 2. Moroccan | 2. a good friend | 2. allow less refugees access to the Netherlands | 2. thinks substantively more positive about this proposal than you |
3. Turkish | 3. an acquaintance | 3. reduce subsidies for sustainability policies (for example electric cars, solar panels and heat pumps) | 3. thinks about the same about this proposal than you | |
4. family (in-laws) | ||||
5. someone you just met |
4 Table 2
Descriptives dependent variable.
We present descriptive for total sample, and per ethnic group. We do this for weighted sample and unweighted. For the total sample we weigh to (representative) Dutch population. For the ethnic group samples we weigh to (representative) ethnic group populations. See the codebook of NELLS for more details.
Our main conclusion is that distributions do not change substantially for weighted and unweighted samples. We therefore continue our analysis on an unweighted sample.
# from wide to long (we have two observation per resondent)
df1 <- df
df2 <- df
df1$index <- 1
df2$index <- 2
df_tot <- rbind(df1, df2)
df_tot$Y <- ifelse(df_tot$index == 1, df_tot$L1, df_tot$L2)
summary(df_tot$Y)#> Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
#> 1.000 3.000 4.000 3.864 5.000 5.000 9314.1 number of respondents for total sample
df_sel <- df[!is.na(df$L1) & !is.na(df$L2), ]
# total
nrow(df_sel)
# etnicity
table(df_sel$egoNL, useNA = "always")
table(df_sel$egoM, useNA = "always")
table(df_sel$egoT, useNA = "always")
# gender
table(df_sel$female, useNA = "always")#> [1] 2545
#>
#> 0 1 <NA>
#> 1064 1481 0
#>
#> 0 1 <NA>
#> 2139 406 0
#>
#> 0 1 <NA>
#> 1910 635 0
#>
#> 0 1 <NA>
#> 1193 1352 0# present result for a weighted sample, and for an unweighted sample
myw <- wtd.mean(df_tot$Y, weights = df_tot$cweight2, normwt = TRUE)
my <- wtd.mean(df_tot$Y)
propyw <- round(prop.table(wtd.table(df_tot$Y, weights = df_tot$cweight2, normwt = TRUE)$sum.of.weights),
3)
propy <- round(prop.table(wtd.table(df_tot$Y)$sum.of.weights), 3)
Nobsw <- round(sum(wtd.table(df_tot$Y, weights = df_tot$cweight2, normwt = TRUE)$sum.of.weights), 3)
Nobs <- round(sum(wtd.table(df_tot$Y)$sum.of.weights), 3)
resw <- c(propyw, myw, Nobsw)
res <- c(propy, my, Nobs)
# Per ethnic group nl
myw <- wtd.mean(df_tot$Y[df_tot$egoNL == 1], weights = df_tot$cweight1[df_tot$egoNL == 1], normwt = TRUE)
my <- wtd.mean(df_tot$Y[df_tot$egoNL == 1])
propyw <- round(prop.table(wtd.table(df_tot$Y[df_tot$egoNL == 1], weights = df_tot$cweight1[df_tot$egoNL ==
1], normwt = TRUE)$sum.of.weights), 3)
propy <- round(prop.table(wtd.table(df_tot$Y[df_tot$egoNL == 1])$sum.of.weights), 3)
Nobsw <- round(sum(wtd.table(df_tot$Y[df_tot$egoNL == 1], weights = df_tot$cweight1[df_tot$egoNL == 1],
normwt = TRUE)$sum.of.weights), 3)
Nobs <- round(sum(wtd.table(df_tot$Y[df_tot$egoNL == 1])$sum.of.weights), 3)
reswN <- c(propyw, myw, Nobsw)
resN <- c(propy, my, Nobs)
# m
myw <- wtd.mean(df_tot$Y[df_tot$egoM == 1], weights = df_tot$cweight1[df_tot$egoM == 1], normwt = TRUE)
my <- wtd.mean(df_tot$Y[df_tot$egoM == 1])
propyw <- round(prop.table(wtd.table(df_tot$Y[df_tot$egoM == 1], weights = df_tot$cweight1[df_tot$egoM ==
1], normwt = TRUE)$sum.of.weights), 3)
propy <- round(prop.table(wtd.table(df_tot$Y[df_tot$egoM == 1])$sum.of.weights), 3)
Nobsw <- round(sum(wtd.table(df_tot$Y[df_tot$egoM == 1], weights = df_tot$cweight1[df_tot$egoM == 1],
normwt = TRUE)$sum.of.weights), 3)
Nobs <- round(sum(wtd.table(df_tot$Y[df_tot$egoM == 1])$sum.of.weights), 3)
reswM <- c(propyw, myw, Nobsw)
resM <- c(propy, my, Nobs)
# t
myw <- wtd.mean(df_tot$Y[df_tot$egoT == 1], weights = df_tot$cweight1[df_tot$egoT == 1], normwt = TRUE)
my <- wtd.mean(df_tot$Y[df_tot$egoT == 1])
propyw <- round(prop.table(wtd.table(df_tot$Y[df_tot$egoT == 1], weights = df_tot$cweight1[df_tot$egoT ==
1], normwt = TRUE)$sum.of.weights), 3)
propy <- round(prop.table(wtd.table(df_tot$Y[df_tot$egoT == 1])$sum.of.weights), 3)
Nobsw <- round(sum(wtd.table(df_tot$Y[df_tot$egoT == 1], weights = df_tot$cweight1[df_tot$egoT == 1],
normwt = TRUE)$sum.of.weights), 0)
Nobs <- round(sum(wtd.table(df_tot$Y[df_tot$egoT == 1])$sum.of.weights), 0)
reswT <- c(propyw, myw, Nobsw)
resT <- c(propy, my, Nobs)
# men
myw <- wtd.mean(df_tot$Y[df_tot$female == 0], weights = df_tot$cweight1[df_tot$female == 0], normwt = TRUE)
my <- wtd.mean(df_tot$Y[df_tot$female == 0])
propyw <- round(prop.table(wtd.table(df_tot$Y[df_tot$female == 0], weights = df_tot$cweight1[df_tot$female ==
0], normwt = TRUE)$sum.of.weights), 3)
propy <- round(prop.table(wtd.table(df_tot$Y[df_tot$female == 0])$sum.of.weights), 3)
Nobsw <- round(sum(wtd.table(df_tot$Y[df_tot$female == 0], weights = df_tot$cweight1[df_tot$female ==
0], normwt = TRUE)$sum.of.weights), 0)
Nobs <- round(sum(wtd.table(df_tot$Y[df_tot$female == 0])$sum.of.weights), 0)
reswMen <- c(propyw, myw, Nobsw)
resMen <- c(propy, my, Nobs)
# women
myw <- wtd.mean(df_tot$Y[df_tot$female == 1], weights = df_tot$cweight1[df_tot$female == 1], normwt = TRUE)
my <- wtd.mean(df_tot$Y[df_tot$female == 1])
propyw <- round(prop.table(wtd.table(df_tot$Y[df_tot$female == 1], weights = df_tot$cweight1[df_tot$female ==
1], normwt = TRUE)$sum.of.weights), 3)
propy <- round(prop.table(wtd.table(df_tot$Y[df_tot$female == 1])$sum.of.weights), 3)
Nobsw <- round(sum(wtd.table(df_tot$Y[df_tot$female == 1], weights = df_tot$cweight1[df_tot$female ==
1], normwt = TRUE)$sum.of.weights), 0)
Nobs <- round(sum(wtd.table(df_tot$Y[df_tot$female == 1])$sum.of.weights), 0)
reswWomen <- c(propyw, myw, Nobsw)
resWomen <- c(propy, my, Nobs)
res2 <- as_tibble(cbind(res, resw, resWomen, reswWomen, resMen, reswMen, resN, reswN, resM, reswM, resT,
reswT))
names <- c("1. stop conversation", "2. change subject", "3. only listen", "4. disclose own opinion",
"5. substantive discussion", "mean", "N observations")
res2 <- res2 %>%
add_column(names, .before = TRUE)
tab2 <- flextable(res2) %>%
add_header_row(values = c(" ", rep(c("unweighted", "weighted"), 6)), top = FALSE) %>%
delete_rows(i = 1, part = "header") %>%
add_header_row(values = c(" ", "Total", "Women", "Men", "Majority Dutch", "Moroccan Dutch", "Turkish Dutch"),
colwidths = c(1, 2, 2, 2, 2, 2, 2)) %>%
colformat_double(digits = 3) %>%
colformat_double(i = 7, digits = 0) %>%
align(i = 1, align = "center", part = "header") %>%
fontsize(size = 8, part = "all") %>%
set_table_properties(layout = "autofit") %>%
add_footer_lines(value = c("Notes: \n- To construct this table both split ballots of NELLS have been used. \n- Number of unique respondents: 2.545 (Total); 1.352 (Women); 1.193 (Men); 1.481 (Majority Dutch); 406 (Moroccan Dutch); 635 (Turkish Dutch).")) %>%
fontsize(size = 8, part = "all") %>%
set_table_properties(layout = "autofit")
# fsave(tab2)
tab2 %>%
set_caption("Table2. Willingness to talk politics - Descriptive Statistics")
| Total | Women | Men | Majority Dutch | Moroccan Dutch | Turkish Dutch | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| unweighted | weighted | unweighted | weighted | unweighted | weighted | unweighted | weighted | unweighted | weighted | unweighted | weighted |
1. stop conversation | 0.032 | 0.025 | 0.025 | 0.022 | 0.039 | 0.040 | 0.023 | 0.023 | 0.045 | 0.047 | 0.042 | 0.041 |
2. change subject | 0.049 | 0.043 | 0.051 | 0.051 | 0.047 | 0.050 | 0.041 | 0.041 | 0.056 | 0.059 | 0.064 | 0.068 |
3. only listen | 0.212 | 0.227 | 0.240 | 0.242 | 0.179 | 0.178 | 0.235 | 0.233 | 0.162 | 0.154 | 0.192 | 0.190 |
4. disclose own opinion | 0.437 | 0.428 | 0.468 | 0.469 | 0.402 | 0.407 | 0.433 | 0.429 | 0.401 | 0.429 | 0.469 | 0.457 |
5. substantive discussion | 0.270 | 0.278 | 0.215 | 0.216 | 0.333 | 0.326 | 0.269 | 0.274 | 0.335 | 0.311 | 0.233 | 0.244 |
mean | 3.864 | 3.892 | 3.797 | 3.804 | 3.941 | 3.929 | 3.885 | 3.890 | 3.925 | 3.899 | 3.785 | 3.794 |
N observations | 5,103 | 5,103 | 2,713 | 2,713 | 2,390 | 2,390 | 2,967 | 2,967 | 817 | 817 | 1,273 | 1,273 |
Notes: | ||||||||||||
5 Appendix 1
We demonstrate that dependent is not normally distributed. We will therefore also dichotomize our dependent variable and estimate a logistic (hierarchical) regression and a Linear Probability Model.
# parameters that will be passed to ``stat_function``
n = sum(!is.na(df_tot$Y))
mean = mean(df_tot$Y, na.rm = T)
sd = sd(df_tot$Y, na.rm = T)
binwidth = 1 # passed to geom_histogram and stat_function
set.seed(1)
df_plot <- data.frame(x = df_tot$Y[!is.na(df_tot$Y)])
appendix1 <- ggplot(df_plot, aes(x = x, mean = mean, sd = sd, binwidth = binwidth, n = n)) + theme_bw() +
geom_histogram(binwidth = binwidth, colour = "white", fill = "cornflowerblue", linewidth = 0.1) +
stat_function(fun = function(x) dnorm(x, mean = mean, sd = sd) * n * binwidth, color = "darkred",
linewidth = 1) + ylab(c("count")) + scale_x_continuous(breaks = c(1:5), label = c("stop \nconversation",
"change \nsubject", "only \nlisten", "disclose \nown opinion", "substantive \ndiscussion"), name = "choice")
# theme(axis.text.x = element_text(angle = 70, vjust = .8, hjust=.9))
appendix1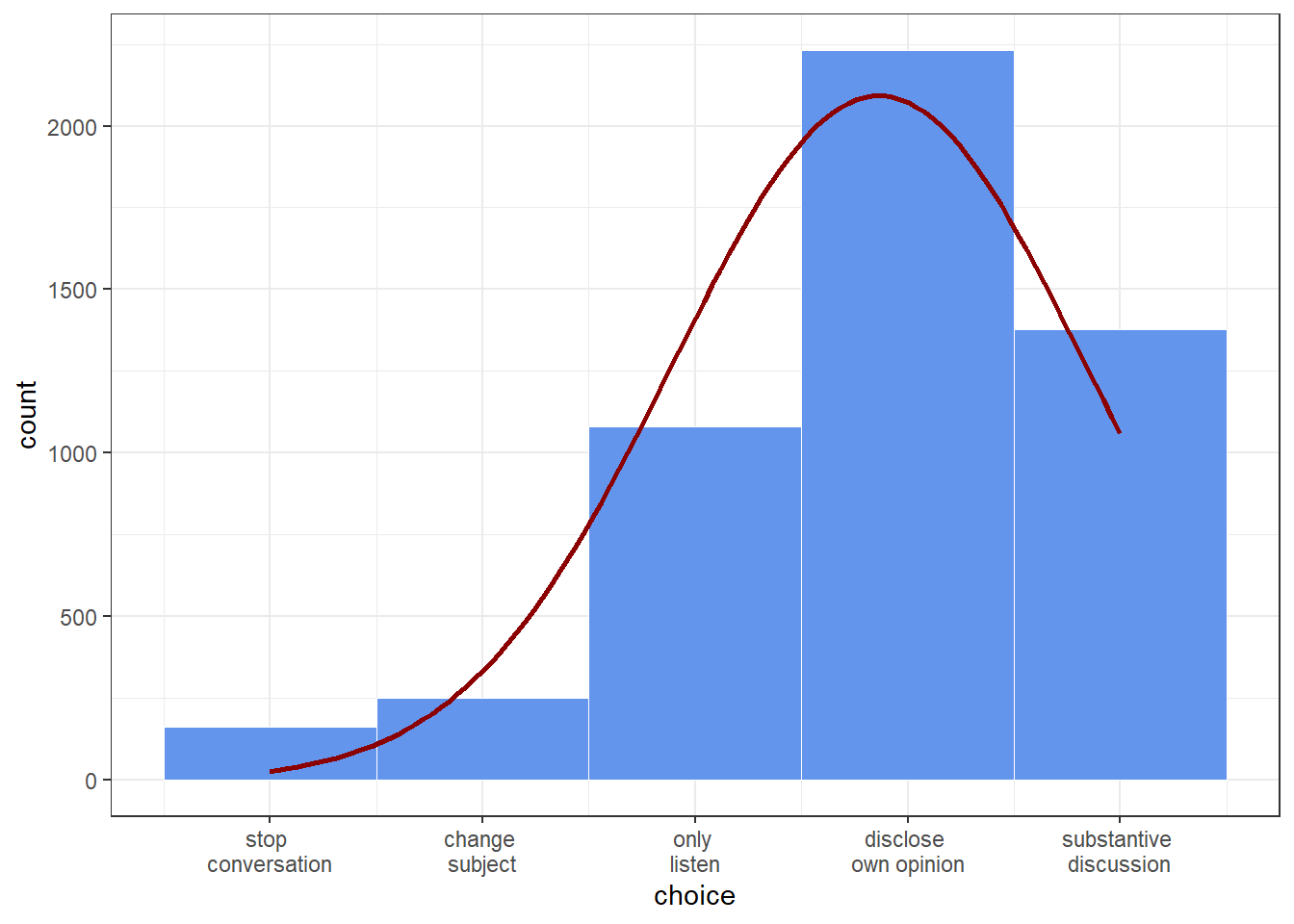
Appendix 1: Distribution of dependent variable
# fsave(appendix1)6 Sample selection
Unique respondents before selection:
length(unique(df_sb2$crespnr))#> [1] 1514# delete respondents if missings on the two observations for the dependent!
table(is.na(df_sb2$L1), is.na(df_sb2$L2))
df_sb2 <- df_sb2[!is.na(df_sb2$L1) & !is.na(df_sb2$L2), ] #266
# delete if missing on main independent vars: gender, ethnicity, age, acquaintanceship network
# gender
table(df_sb2$female, useNA = "always") #0
# ethnicity
table(df_sb2$egoO, useNA = "always") #12
# age
table(is.na(df_sb2$cage)) #age: 2
# educ
table(is.na(df_sb2$C05)) #educ: 0
# network
table(is.na(df_sb2$netsover3), useNA = "always") #98
# listwise deletion
df_sb2 <- df_sb2[!is.na(df_sb2$egoO) & !is.na(df_sb2$cage) & !is.na(df_sb2$netsover3), ]
# #missings additional controls (no listwise deletion, these controls only in robustness)
# table(is.na(df_sb2$H19i))#thermoN: 166 table(is.na(df_sb2$H19j))#thermoN: 129
# table(is.na(df_sb2$H19k))#thermoN: 118 table(is.na(df_sb2$ego_opinion1)) # 3
# table(is.na(df_sb2$ego_opinion1b)) table(is.na(df_sb2$ego_opinion2))#: 3
# table(is.na(df_sb2$ego_opinion3))# 0 table(is.na(df_sb2$H06)) #political interest: 0 #district
# vars table(is.na(df_sb2$district_EI_ethnic))#>
#> FALSE TRUE
#> FALSE 1242 4
#> TRUE 2 266
#>
#> 0 1 <NA>
#> 591 651 0
#>
#> 0 1 <NA>
#> 1230 12 0
#>
#> FALSE TRUE
#> 1240 2
#>
#> FALSE
#> 1242
#>
#> FALSE TRUE <NA>
#> 1144 98 0Unique respondents after selection:
length(unique(df_sb2$crespnr)) #1143#> [1] 11437 Table 3
Descriptive statistics working sample (split ballot 2).
select2 <- c("female", "egoNL", "egoM", "egoT", "netsover3", "hhi_gender", "hhi_ethnic", "cage", "educL",
"educM", "educH")
df_sel2 <- df_sb2[, select2]
table_des <- psych::describe(df_sel2)
table_des$missing <- colSums(is.na(df_sel2))
table3 <- table_des %>%
mutate(variable = rownames(table_des)) %>%
select(variable, mean, sd, min, max) %>%
flextable() %>%
set_caption("Table 3. Descriptive statistics independent variables (respondent-level)") %>%
colformat_double(j = c("min", "max"), digits = c(0), big.mark = "") %>%
colformat_double(j = c("mean", "sd"), digits = c(3), big.mark = "") %>%
colformat_double(i = c(6, 7), j = c("min", "max"), digits = c(3), big.mark = "") %>%
set_header_labels(mean = "mean / \nproportion") %>%
mk_par(j = 1, value = as_paragraph(c("Women", "Ethnicity \n\n \t Native-Dutch", "\t Moroccan-Dutch",
"\t Turkish-Dutch", "Network size", "Network gender diversity", "Network ethnic diversity", "Age",
"Education \n\n \t Primary", "\t Secondary", "\t Tertiary"))) %>%
valign(valign = "bottom", part = "body") %>%
width(j = 1, width = 60, unit = "mm") %>%
add_footer_row(values = c("N = 1,143"), colwidths = 5)
table3
# fsave(table3)variable | mean / | sd | min | max |
|---|---|---|---|---|
Women | 0.529 | 0.499 | 0 | 1 |
Ethnicity | 0.610 | 0.488 | 0 | 1 |
Moroccan-Dutch | 0.144 | 0.352 | 0 | 1 |
Turkish-Dutch | 0.239 | 0.427 | 0 | 1 |
Network size | 532.579 | 348.162 | 89 | 2691 |
Network gender diversity | 0.407 | 0.139 | 0.000 | 0.500 |
Network ethnic diversity | 0.307 | 0.232 | 0.000 | 0.667 |
Age | 31.857 | 8.815 | 16 | 55 |
Education | 0.146 | 0.353 | 0 | 1 |
Secondary | 0.382 | 0.486 | 0 | 1 |
Tertiary | 0.472 | 0.499 | 0 | 1 |
N = 1,143 | ||||
8 Multivariate analyses
Dutch description of vignette.
Module L: Vignette Er volgen nu twee verschillende situaties over politieke gesprekken. We vragen u om zich in deze situatie in te beelden. We zijn benieuwd naar wat u zou doen.
We begrijpen dat de situaties mogelijk niet (vaak) voorkomen in uw dagelijks leven. Probeer de vraag toch te beantwoorden.
L1: Stelt u zich voor dat u een {e://Field/gender1} van {e://Field/groep1} afkomst tegenkomt. Dit zou bijvoorbeeld kunnen zijn op straat, het openbaar vervoer, op uw werk, of bij een (sport)vereniging. Deze persoon is {e://Field/relatie1}. Deze persoon knoopt met u een praatje aan.
Na een tijdje komt het recente politieke voorstel ter sprake om {e://Field/issue1}. Het wordt duidelijk dat deze persoon {e://Field/positie1}.
Wat doet u?
- Ik stop het gesprek.
- Ik probeer het gesprek op een ander onderwerp te krijgen.
- Ik luister naar de ander: Ik geef niet mijn eigen mening en vermijd een inhoudelijke discussie.
- Ik ga in gesprek: Ik geef mijn eigen mening, maar vermijd een inhoudelijke discussie.
- Ik ga in discussie: Ik geef mijn eigen mening en bespreek argumenten voor en tegen.
L2: Stelt u zich voor dat u een {e://Field/gender2} van {e://Field/groep2} afkomst tegenkomt. Dit zou bijvoorbeeld kunnen zijn op straat, het openbaar vervoer, op uw werk, of bij een (sport)vereniging. Deze persoon is ${e://Field/relatie2}. Deze persoon knoopt met u een praatje aan.
Na een tijdje komt het recente politieke voorstel ter sprake om {e://Field/issue2}. Het wordt duidelijk dat deze persoon ${e://Field/positie2}.
Wat doet u?
- Ik stop het gesprek.
- Ik probeer het gesprek op een ander onderwerp te krijgen.
- Ik luister naar de ander: Ik geef niet mijn eigen mening en vermijd een inhoudelijke discussie.
- Ik ga in gesprek: Ik geef mijn eigen mening, maar vermijd een inhoudelijke discussie.
- Ik ga in discussie: Ik geef mijn eigen mening en bespreek argumenten voor en tegen.
Vignette dimensies: Gender: 1. Man 2. Vrouw Groep: 1. Marokkaanse 2. Nederlandse 3. Turkse Relatie 1. een collega 2. een goede vriend(in) 3. een kennis 4. familie (aangetrouwd) 5. iemand die je net bent tegengekomen Issue: 1. hogere belastingen voor mensen met topinkomens in te voeren 2. minder vluchtelingen op te nemen in Nederland 3. subsidies op maatregelen die duurzaamheid vergroten (bijvoorbeeld elektrische auto’s, zonnepanelen en warmtepompen) af te bouwen Positie 1. een stuk negatiever denkt over dit voorstel dan u 2. een stuk positiever denkt over dit voorstel dan u 3. ongeveer hetzelfde denkt over dit voorstel als u
8.1 Nested linear
We nest the observations within the respondent-level.
select <- c("crespnr", "L1", "L2", "cL1_gender", "cL2_gender", "cL1_relatie", "cL2_relatie", "cL1_issue",
"cL2_issue", "cL1_positie", "cL2_positie", "cL1_groep", "cL2_groep", "female", "egoNL", "egoM", "egoT",
"ego_gen1", "cage", "educL", "educM", "educH", "educ_current", "thermoD", "thermoM", "thermoT", "ego_opinion1",
"ego_opinion2", "ego_opinion3", "polint", "cdn_tot", "cdn_tot_nk", "cdn_EI_ethnic", "cdn_EI_gender",
"netsover3", "nsum_EI_ethnic", "nsum_EI_gender", "hhi_educ", "hhi_gender", "hhi_ethnic", "district_EI_ethnic",
"district_EI_gender")
df_sel <- df_sb2[, select]
df1 <- df_sel
df2 <- df_sel
df1$index <- 1
df2$index <- 2
df_tot <- rbind(df1, df2)
df_tot$Y_L <- ifelse(df_tot$index == 1, df_tot$L1, df_tot$L2)
df_tot$L_gender <- ifelse(df_tot$index == 1, df_tot$cL1_gender, df_tot$cL2_gender)
df_tot$L_relatie <- ifelse(df_tot$index == 1, df_tot$cL1_relatie, df_tot$cL2_relatie)
df_tot$L_issue <- ifelse(df_tot$index == 1, df_tot$cL1_issue, df_tot$cL2_issue)
df_tot$L_positie <- ifelse(df_tot$index == 1, df_tot$cL1_positie, df_tot$cL2_positie)
df_tot$L_groep <- ifelse(df_tot$index == 1, df_tot$cL1_groep, df_tot$cL2_groep)We recode position for issue1 so in same ‘right-wing’ direction. So for position, more positive means more ‘right-wing’.
df_tot <- df_tot %>%
mutate(L_positie = case_when(L_issue == 1 ~ case_match(L_positie, 1 ~ 2, 2 ~ 1, 3 ~ 3), .default = L_positie))We match the political opinion of the respondent to the correct policy measure/issue as presented in the vignette. We do not use this in the main manuscript.
df_tot <- df_tot %>%
mutate(ego_opinion = case_when(L_issue == 1 ~ ego_opinion1, .default = NA), ego_opinion = case_when(L_issue ==
2 ~ ego_opinion2, .default = ego_opinion), ego_opinion = case_when(L_issue == 3 ~ ego_opinion3,
.default = ego_opinion))We change some reference categories.
df_tot$L_groep <- relevel(as.factor(df_tot$L_groep), 2) #dutch ref
df_tot$L_positie <- relevel(as.factor(df_tot$L_positie), 3) #same refWe bin some categories in the relation dimension into ‘weak’ and ‘strong’ ties.
# attributes(df_tot$cL1_relatie)
df_tot <- df_tot %>%
mutate(L_relatie2 = case_match(L_relatie, c(1, 3, 5) ~ "weak", c(2, 4) ~ "strong"))Similarly we bin categories in the political distance dimension into ‘same’ and ‘different’.
# attributes(df_tot$cL1_positie)
df_tot <- df_tot %>%
mutate(L_positie2 = case_match(L_positie, c("1", "2") ~ "different", c("3") ~ "same"))Dyadic similarity measures
Dyadic similarity is based on ego’s characteristics and the characteristic of alter, as described in the vignette.
df_tot <- df_tot %>%
mutate(gen_sim = case_when((L_gender == 1 & female == 0) | (L_gender == 2 & female == 1) ~ 1, .default = 0),
ethnic_sim = case_when((L_groep == 1 & egoM == 1) | (L_groep == 2 & egoNL == 1) | (L_groep ==
3 & egoT == 1) ~ 1, .default = 0))Or our robustness analysis per ethnic group we think it is more intuitive to construct a dyadic variable indicating whether the alter belongs to an ethnic/gender outgroup.
df_tot <- df_tot %>%
mutate(outgroup = case_when((L_groep == 1 & egoNL == 1) | (L_groep == 3 & egoNL == 1) ~ 1, (L_groep ==
2 & egoM == 1) | (L_groep == 3 & egoM == 1) ~ 1, (L_groep == 1 & egoT == 1) | (L_groep == 2 &
egoT == 1) ~ 1, .default = 0))We will fit models with the R package lme4 (Bates et al. 2015). From past experience, we
know reviewers like p-values. However, there is a reason why in lmer
p-values are not reported by default: [(https://stat.ethz.ch/pipermail/r-help/2006-May/094765.html)].
We use the R package jtools (Long
2022) for these purposes. Perhaps better is to report CI.
8.2 Overview hypotheses
- the likelihood of political talk increases when potential discussion
partners share a (a) gender, (b) ethnic background, or (c) congruent
political views (H1).
- the likelihood of political talk increases when potential discussion
partners are strong rather than weak ties (H2).
- the positive effect of (a) gender and (b) ethnic background
similarity between potential discussion partners on political talk
increases when discussion partners are weak (i.e., colleagues,
acquaintances) rather than strong ties (i.e., good friends, family
members) (H3).
- individuals with larger acquaintanceship networks are more likely to
engage in political talk (H4).
- individuals with more (a) gender and (b) ethnically diverse acquaintanceship networks are more likely to engage in political talk (H5).
- the positive effect of gender background similarity between potential discussion partners on political talk decreases when the respondent’s network is more gender diverse; (b) the positive effect of ethnic background similarity between potential discussion partners on political talk decreases when the respondent’s network is more ethnically diverse;
# Model empty in appendix?
M_empty <- (lmer(Y_L ~ +(1 | crespnr), data = df_tot))
# Model 0 in appendix?
M0 <- (lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie) + as.factor(L_issue) +
as.factor(L_positie) + as.factor(L_groep) + (1 | crespnr), data = df_tot))
# hypo1 / hypo2
M1 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + female + egoM + egoT + gen_sim + ethnic_sim + cage + educM + educH + (1 |
crespnr), data = df_tot)
# hypo3
M2 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + female + egoM + egoT + gen_sim + ethnic_sim + cage + educM + educH + as.factor(L_relatie2) *
gen_sim + as.factor(L_relatie2) * ethnic_sim + as.factor(L_relatie2) * as.factor(L_positie2) + (1 |
crespnr), data = df_tot)
# hypo 4 / 5 M3_alt <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_relatie2) + as.factor(L_issue)
# + as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage
# + educM + educH + log(netsover3) + hhi_gender + hhi_ethnic + cage + educM + educH + (1 |
# crespnr), data=df_tot )
M3 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage +
educM + educH + log(netsover3) + hhi_gender + hhi_ethnic + as.factor(L_relatie2) * gen_sim + as.factor(L_relatie2) *
ethnic_sim + as.factor(L_relatie2) * as.factor(L_positie2) + (1 | crespnr), data = df_tot)
# based on suggestion reviewer, without family members
M3_RR1 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage +
educM + educH + log(netsover3) + hhi_gender + hhi_ethnic + as.factor(L_relatie2) * gen_sim + as.factor(L_relatie2) *
ethnic_sim + as.factor(L_relatie2) * as.factor(L_positie2) + (1 | crespnr), data = df_tot[df_tot$L_relatie !=
4, ])
# summary(M3_RR1)
M4 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage +
educM + educH + as.factor(L_relatie2) * gen_sim + as.factor(L_relatie2) * ethnic_sim + as.factor(L_relatie2) *
as.factor(L_positie2) + log(netsover3) + hhi_gender + hhi_ethnic + gen_sim * hhi_gender + gen_sim *
hhi_ethnic + cage + educM + educH + (1 | crespnr), data = df_tot)pvalue_format <- function(x) {
# p <- 2*pt(q=x, df=1000, lower.tail=FALSE)
z <- cut(x, breaks = c(-Inf, 0.001, 0.01, 0.05, 0.1, Inf), labels = c("***", "**", "*", "~", ""))
as.character(z)
}
df_M0 <- as_tibble(summ(M0)$coeftable) %>%
mutate(terms = rownames(summ(M0)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M1 <- as_tibble(summ(M1)$coeftable) %>%
mutate(terms = rownames(summ(M1)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M2 <- as_tibble(summ(M2)$coeftable) %>%
mutate(terms = rownames(summ(M2)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M3 <- as_tibble(summ(M3)$coeftable) %>%
mutate(terms = rownames(summ(M3)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M4 <- as_tibble(summ(M4)$coeftable) %>%
mutate(terms = rownames(summ(M4)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_models <- full_join(df_M1, df_M2, by = c("terms")) %>%
full_join(y = df_M3, by = c("terms")) %>%
full_join(y = df_M4, by = c("terms"))8.3 Appendix 2
We report the null-model (original categories vignette, no other covariates) in Appendix 2 of the manuscript.
vars_empty <- as.data.frame(VarCorr(M_empty))
# summary(M0)
vars <- as.data.frame(VarCorr(M0))
# round(vars$vcov,3)
appendix2 <- df_M0 %>%
flextable() %>%
add_header_row(values = c(" ", c("Estimate", " ", "Std.Error")), top = FALSE) %>%
delete_rows(i = 1, part = "header") %>%
align(i = 1, align = "center", part = "header") %>%
align(j = 3, align = "left") %>%
padding(padding.left = 0, j = c(3), part = "all") %>%
padding(padding.right = 0, j = c(2), part = "all") %>%
valign(valign = "bottom", part = "body") %>%
width(j = 1, width = 60, unit = "mm") %>%
mk_par(j = 1, value = as_paragraph(c("Intercept", "Alter gender (men = ref.) \n\n\t woman", "Ethnic background alter (native Dutch = ref.) \n\n\t Moroccan",
"\t Turkish", "Relationship type (colleague = ref.) \n\n\t friend", "\t acquaintance", "\t family",
"\t stranger", "Policy (higher tax for high incomes = ref.) \n\n\t less refugees", "\t reduce climate subsidies",
"Political distance (similar = ref.) \n\n\t more negative", "\t more positive"))) %>%
colformat_double(j = c(2, 4), digits = 3) %>%
add_body_row(values = c("R^2_resp.", round(100 * (vars_empty$vcov[1] - vars$vcov[1])/vars_empty$vcov[1],
3)), colwidths = c(1, 3), top = FALSE) %>%
add_body_row(values = c("R^2_obs.", round(100 * (vars_empty$vcov[2] - vars$vcov[2])/vars_empty$vcov[2],
3)), colwidths = c(1, 3), top = FALSE) %>%
align(i = c(13, 14), j = c(2:4), align = "center", part = "body") %>%
border_inner_h(border = fp_border_default(width = 0), part = "body") %>%
hline(i = 12) %>%
add_footer_lines(value = c("***p<.001, **p<.01, *p<.05, ~p<.10")) %>%
add_footer_lines(value = c("N_obs = 2,286; N_resp = 1,142")) %>%
fontsize(size = 8, part = "all") %>%
set_table_properties(layout = "autofit")
appendix2 %>%
set_caption("Appendix 2: predicting political talk with vignette characteristics only")
# fsave(appendix2)
| Estimate |
| Std.Error |
|---|---|---|---|
Intercept | 3.922 | *** | 0.057 |
Alter gender (men = ref.) | -0.000 | 0.030 | |
Ethnic background alter (native Dutch = ref.) | -0.084 | * | 0.036 |
Turkish | -0.061 | ~ | 0.036 |
Relationship type (colleague = ref.) | 0.112 | * | 0.048 |
acquaintance | 0.046 | 0.048 | |
family | 0.060 | 0.048 | |
stranger | -0.000 | 0.048 | |
Policy (higher tax for high incomes = ref.) | -0.033 | 0.036 | |
reduce climate subsidies | 0.015 | 0.036 | |
Political distance (similar = ref.) | -0.057 | 0.036 | |
more positive | 0.028 | 0.037 | |
R^2_resp. | 0.04 | ||
R^2_obs. | 0.673 | ||
***p<.001, **p<.01, *p<.05, ~p<.10 | |||
N_obs = 2,286; N_resp = 1,142 | |||
8.4 Table 4
varsm1 <- as.data.frame(VarCorr(M1))
varsm2 <- as.data.frame(VarCorr(M2))
varsm3 <- as.data.frame(VarCorr(M3))
varsm4 <- as.data.frame(VarCorr(M4))
table4 <- df_models %>%
flextable() %>%
add_header_row(values = c(" ", rep(c("Estimate", " ", "Std.Error"), 4)), top = FALSE) %>%
delete_rows(i = 1, part = "header") %>%
add_header_row(values = c(" ", "Model 1", "Model 2", "Model 3", "Model 4"), colwidths = c(1, 3, 3,
3, 3)) %>%
align(i = 1, align = "center", part = "header") %>%
align(j = c(3, 6, 9, 12), align = "left") %>%
padding(padding.left = 0, j = c(3, 6, 9, 12), part = "all") %>%
padding(padding.right = 0, j = c(2, 5, 8, 11), part = "all") %>%
mk_par(j = 1, value = as_paragraph(c("Intercept", "Gender alter (men = ref.) \n\n\t woman", "Ethnic background alter (native Dutch = ref.) \n\n\t Moroccan",
"\t Turkish", "Tie strength (strong = ref.) \n\n\t weak", "Policy (higher tax for high incomes = ref.) \n\n\t less refugees",
"\t reduce climate subsidies", "Political distance (different = ref.) \n\n\t similar", "Gender ego (men =ref.) \n\n\t woman",
"Ethnic background ego (native Dutch = ref.) \n\n\t Moroccan", "\t Turkish", "Gender similarity dyad",
"Ethnic similarity dyad", "Age ego", "Education ego (primary =ref.) \n\n\t secondary", "\t tertiary",
"Weak tie * gender similarity", "Weak tie * ethnic similarity", "Weak tie * opinion similarity",
"Network size", "Network gender diversity", "Network ethnic diversity", "Gender similarity * gender diversity",
"Ethnic similarity * ethnic diversity"))) %>%
valign(valign = "bottom", part = "body") %>%
width(j = 1, width = 60, unit = "mm") %>%
add_footer_lines(value = c("***p<.001, **p<.01, *p<.05, ~p<.10")) %>%
add_footer_lines(value = c("N_obs = 2,286; N_resp = 1,142")) %>%
colformat_double(digits = 3) %>%
add_body_row(values = c("var_resp.", c(round(varsm1$vcov, 3)[1], round(varsm2$vcov, 3)[1], round(varsm3$vcov,
3)[1], round(varsm4$vcov, 3)[1])), colwidths = c(1, 3, 3, 3, 3), top = FALSE) %>%
add_body_row(values = c("var_obs.", c(round(varsm1$vcov, 3)[2], round(varsm2$vcov, 3)[2], round(varsm3$vcov,
3)[2], round(varsm4$vcov, 3)[2])), colwidths = c(1, 3, 3, 3, 3), top = FALSE) %>%
align(i = c(25, 26), j = c(2:13), align = "center", part = "body") %>%
border_inner_h(border = fp_border_default(width = 0), part = "body") %>%
hline(i = 24) %>%
fontsize(size = 8, part = "all") %>%
set_table_properties(layout = "autofit")
table4 %>%
set_caption("Table 4. Willingness to talk politics")
# fsave(table4)
| Model 1 | Model 2 | Model 3 | Model 4 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate |
| Std.Error | Estimate |
| Std.Error | Estimate |
| Std.Error | Estimate |
| Std.Error |
Intercept | 3.729 | *** | 0.122 | 3.794 | *** | 0.124 | 3.901 | *** | 0.325 | 3.946 | *** | 0.329 |
Gender alter (men = ref.) | -0.001 | 0.030 | -0.001 | 0.030 | -0.001 | 0.030 | 0.005 | 0.030 | ||||
Ethnic background alter (native Dutch = ref.) | -0.059 | 0.040 | -0.061 | 0.040 | -0.061 | 0.040 | -0.063 | 0.040 | ||||
Turkish | -0.048 | 0.039 | -0.044 | 0.039 | -0.044 | 0.039 | -0.045 | 0.039 | ||||
Tie strength (strong = ref.) | -0.069 | * | 0.030 | -0.185 | *** | 0.051 | -0.186 | *** | 0.051 | -0.184 | *** | 0.051 |
Policy (higher tax for high incomes = ref.) | -0.031 | 0.036 | -0.036 | 0.036 | -0.037 | 0.036 | -0.036 | 0.036 | ||||
reduce climate subsidies | 0.014 | 0.036 | 0.018 | 0.036 | 0.015 | 0.036 | 0.017 | 0.036 | ||||
Political distance (different = ref.) | 0.016 | 0.032 | -0.048 | 0.049 | -0.050 | 0.049 | -0.049 | 0.049 | ||||
Gender ego (men =ref.) | -0.246 | *** | 0.052 | -0.246 | *** | 0.052 | -0.249 | *** | 0.052 | -0.248 | *** | 0.052 |
Ethnic background ego (native Dutch = ref.) | 0.096 | 0.076 | 0.089 | 0.076 | -0.016 | 0.085 | -0.016 | 0.086 | ||||
Turkish | -0.046 | 0.062 | -0.049 | 0.062 | -0.146 | * | 0.073 | -0.146 | * | 0.073 | ||
Gender similarity dyad | 0.045 | 0.030 | -0.048 | 0.046 | -0.045 | 0.046 | -0.128 | 0.097 | ||||
Ethnic similarity dyad | 0.028 | 0.035 | 0.040 | 0.051 | 0.041 | 0.051 | 0.044 | 0.051 | ||||
Age ego | -0.000 | 0.003 | -0.000 | 0.003 | -0.001 | 0.003 | -0.001 | 0.003 | ||||
Education ego (primary =ref.) | 0.305 | *** | 0.080 | 0.305 | *** | 0.080 | 0.311 | *** | 0.080 | 0.306 | *** | 0.080 |
tertiary | 0.515 | *** | 0.081 | 0.513 | *** | 0.081 | 0.531 | *** | 0.081 | 0.530 | *** | 0.081 |
Weak tie * gender similarity | 0.166 | ** | 0.060 | 0.162 | ** | 0.060 | 0.159 | ** | 0.060 | |||
Weak tie * ethnic similarity | -0.010 | 0.064 | -0.009 | 0.064 | -0.013 | 0.064 | ||||||
Weak tie * opinion similarity | 0.113 | ~ | 0.064 | 0.116 | ~ | 0.064 | 0.113 | ~ | 0.064 | |||
Network size | -0.046 | 0.052 | -0.046 | 0.052 | ||||||||
Network gender diversity | 0.231 | 0.208 | 0.231 | 0.234 | ||||||||
Network ethnic diversity | 0.374 | ** | 0.140 | 0.234 | 0.155 | |||||||
Gender similarity * gender diversity | -0.001 | 0.211 | ||||||||||
Ethnic similarity * ethnic diversity | 0.275 | * | 0.129 | |||||||||
var_resp. | 0.61 | 0.606 | 0.602 | 0.604 | ||||||||
var_obs. | 0.294 | 0.293 | 0.293 | 0.292 | ||||||||
***p<.001, **p<.01, *p<.05, ~p<.10 | ||||||||||||
N_obs = 2,286; N_resp = 1,142 | ||||||||||||
8.4.1 without families as strong ties
An anonymous reviewer raised the question to what extent results are impacted by unrealistic scenario’s. In our opinion, only - or at least especially - scenarios involving family members may have been unrealistic. We therefore re-estimate model 0 and without family members.
8.4.1.1 Model 0
levels(df_tot$L_relatie)
# Model 0
M0_nofamily <- (lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie) + as.factor(L_issue) +
as.factor(L_positie) + as.factor(L_groep) + (1 | crespnr), data = df_tot[df_tot$L_relatie != 4, ]))
summary(M0_nofamily)
vars <- as.data.frame(VarCorr(M0_nofamily))
# round(vars$vcov,3)
pvalue_format <- function(x) {
# p <- 2*pt(q=x, df=1000, lower.tail=FALSE)
z <- cut(x, breaks = c(-Inf, 0.001, 0.01, 0.05, 0.1, Inf), labels = c("***", "**", "*", "~", ""))
as.character(z)
}
df_M0_nofamily <- as_tibble(summ(M0_nofamily)$coeftable) %>%
mutate(terms = rownames(summ(M0_nofamily)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
RR1 <- df_M0_nofamily %>%
flextable() %>%
add_header_row(values = c(" ", c("Estimate", " ", "Std.Error")), top = FALSE) %>%
delete_rows(i = 1, part = "header") %>%
align(i = 1, align = "center", part = "header") %>%
align(j = 3, align = "left") %>%
padding(padding.left = 0, j = c(3), part = "all") %>%
padding(padding.right = 0, j = c(2), part = "all") %>%
valign(valign = "bottom", part = "body") %>%
width(j = 1, width = 60, unit = "mm") %>%
mk_par(j = 1, value = as_paragraph(c("Intercept", "Alter gender (men = ref.) \n\n\t woman", "Ethnic background alter (native Dutch = ref.) \n\n\t Moroccan",
"\t Turkish", "Relationship type (colleague = ref.) \n\n\t friend", "\t acquaintance", "\t stranger",
"Policy (higher tax for high incomes = ref.) \n\n\t less refugees", "\t reduce climate subsidies",
"Political distance (similar = ref.) \n\n\t more negative", "\t more positive"))) %>%
colformat_double(j = c(2, 4), digits = 3) %>%
add_body_row(values = c("var_resp.", round(vars$vcov[1], 3)), colwidths = c(1, 3), top = FALSE) %>%
add_body_row(values = c("var_obs.", round(vars$vcov[2], 3)), colwidths = c(1, 3), top = FALSE) %>%
align(i = c(12, 13), j = c(2:4), align = "center", part = "body") %>%
border_inner_h(border = fp_border_default(width = 0), part = "body") %>%
hline(i = 11) %>%
add_footer_lines(value = c("***p<.001, **p<.01, *p<.05, ~p<.10")) %>%
add_footer_lines(value = c("N_obs = 1,806; N_resp = 1,092")) %>%
fontsize(size = 8, part = "all") %>%
set_table_properties(layout = "autofit")
RR1 %>%
set_caption("RR1: predicting political talk with vignette characteristics only (excluding vignettes involving family members")#> NULL
#> Linear mixed model fit by REML ['lmerMod']
#> Formula: Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie) +
#> as.factor(L_issue) + as.factor(L_positie) + as.factor(L_groep) + (1 | crespnr)
#> Data: df_tot[df_tot$L_relatie != 4, ]
#>
#> REML criterion at convergence: 4596.6
#>
#> Scaled residuals:
#> Min 1Q Median 3Q Max
#> -3.9621 -0.3341 0.0615 0.4031 3.2840
#>
#> Random effects:
#> Groups Name Variance Std.Dev.
#> crespnr (Intercept) 0.6383 0.7989
#> Residual 0.2970 0.5450
#> Number of obs: 1806, groups: crespnr, 1092
#>
#> Fixed effects:
#> Estimate Std. Error t value
#> (Intercept) 3.932109 0.064028 61.412
#> as.factor(L_gender)2 -0.005721 0.035557 -0.161
#> as.factor(L_groep)1 -0.078478 0.042863 -1.831
#> as.factor(L_groep)3 -0.066095 0.043417 -1.522
#> as.factor(L_relatie)2 0.116116 0.050609 2.294
#> as.factor(L_relatie)3 0.068284 0.050770 1.345
#> as.factor(L_relatie)5 0.023909 0.050324 0.475
#> as.factor(L_issue)2 -0.044314 0.042529 -1.042
#> as.factor(L_issue)3 0.040511 0.042953 0.943
#> as.factor(L_positie)1 -0.097372 0.042968 -2.266
#> as.factor(L_positie)2 0.002950 0.044329 0.067
#>
#> Correlation of Fixed Effects:
#> (Intr) as.fctr(L_g)2 as.fctr(L_g)1 as.fctr(L_g)3 as.fctr(L_r)2 as.fctr(L_r)3 a.(L_)5
#> as.fctr(L_g)2 -0.308
#> as.fctr(L_g)1 -0.329 -0.003
#> as.fctr(L_g)3 -0.375 0.002 0.493
#> as.fctr(L_r)2 -0.418 0.039 -0.022 -0.018
#> as.fctr(L_r)3 -0.405 0.018 -0.036 -0.018 0.531
#> as.fct(L_)5 -0.405 0.038 -0.010 0.001 0.532 0.528
#> as.fctr(L_s)2 -0.361 0.036 0.016 0.072 -0.024 -0.025 -0.001
#> as.fctr(L_s)3 -0.351 0.019 -0.002 0.058 0.005 0.006 -0.007
#> as.fctr(L_p)1 -0.373 -0.005 0.029 0.041 0.001 0.006 -0.038
#> as.fctr(L_p)2 -0.346 0.000 0.009 0.061 -0.003 0.001 -0.046
#> as.fctr(L_s)2 as.fctr(L_s)3 as.fctr(L_p)1
#> as.fctr(L_g)2
#> as.fctr(L_g)1
#> as.fctr(L_g)3
#> as.fctr(L_r)2
#> as.fctr(L_r)3
#> as.fct(L_)5
#> as.fctr(L_s)2
#> as.fctr(L_s)3 0.495
#> as.fctr(L_p)1 0.035 0.031
#> as.fctr(L_p)2 -0.004 -0.025 0.524
| Estimate |
| Std.Error |
|---|---|---|---|
Intercept | 3.932 | *** | 0.064 |
Alter gender (men = ref.) | -0.006 | 0.036 | |
Ethnic background alter (native Dutch = ref.) | -0.078 | ~ | 0.043 |
Turkish | -0.066 | 0.043 | |
Relationship type (colleague = ref.) | 0.116 | * | 0.051 |
acquaintance | 0.068 | 0.051 | |
stranger | 0.024 | 0.050 | |
Policy (higher tax for high incomes = ref.) | -0.044 | 0.043 | |
reduce climate subsidies | 0.041 | 0.043 | |
Political distance (similar = ref.) | -0.097 | * | 0.043 |
more positive | 0.003 | 0.044 | |
var_resp. | 0.638 | ||
var_obs. | 0.297 | ||
***p<.001, **p<.01, *p<.05, ~p<.10 | |||
N_obs = 1,806; N_resp = 1,092 | |||
8.4.1.2 Model 3
# based on suggestion reviewer, without family members
M3_RR1 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage +
educM + educH + log(netsover3) + hhi_gender + hhi_ethnic + as.factor(L_relatie2) * gen_sim + as.factor(L_relatie2) *
ethnic_sim + as.factor(L_relatie2) * as.factor(L_positie2) + (1 | crespnr), data = df_tot[df_tot$L_relatie !=
4, ])
# summary(M3_RR1)
vars <- as.data.frame(VarCorr(M3_RR1))
pvalue_format <- function(x) {
# p <- 2*pt(q=x, df=1000, lower.tail=FALSE)
z <- cut(x, breaks = c(-Inf, 0.001, 0.01, 0.05, 0.1, Inf), labels = c("***", "**", "*", "~", ""))
as.character(z)
}
df_M3_RR1 <- as_tibble(summ(M3_RR1)$coeftable) %>%
mutate(terms = rownames(summ(M3_RR1)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
RR2 <- df_M3_RR1 %>%
flextable() %>%
add_header_row(values = c(" ", c("Estimate", " ", "Std.Error")), top = FALSE) %>%
delete_rows(i = 1, part = "header") %>%
align(i = 1, align = "center", part = "header") %>%
align(j = 3, align = "left") %>%
padding(padding.left = 0, j = c(3), part = "all") %>%
padding(padding.right = 0, j = c(2), part = "all") %>%
valign(valign = "bottom", part = "body") %>%
width(j = 1, width = 60, unit = "mm") %>%
mk_par(j = 1, value = as_paragraph(c("Intercept", "Gender alter (men = ref.) \n\n\t woman", "Ethnic background alter (native Dutch = ref.) \n\n\t Moroccan",
"\t Turkish", "Tie strength (strong = ref.) \n\n\t weak", "Policy (higher tax for high incomes = ref.) \n\n\t less refugees",
"\t reduce climate subsidies", "Political distance (different = ref.) \n\n\t similar", "Gender ego (men =ref.) \n\n\t woman",
"Ethnic background ego (native Dutch = ref.) \n\n\t Moroccan", "\t Turkish", "Gender similarity dyad",
"Ethnic similarity dyad", "Age ego", "Education ego (primary =ref.) \n\n\t secondary", "\t tertiary",
"Network size", "Network gender diversity", "Network ethnic diversity", "Weak tie * gender similarity",
"Weak tie * ethnic similarity", "Weak tie * opinion similarity"))) %>%
valign(valign = "bottom", part = "body") %>%
width(j = 1, width = 60, unit = "mm") %>%
add_footer_lines(value = c("***p<.001, **p<.01, *p<.05, ~p<.10")) %>%
add_footer_lines(value = c("N_obs = 1,806; N_resp = 1,092")) %>%
colformat_double(digits = 3) %>%
add_body_row(values = c("var_resp.", c(round(vars$vcov, 3)[1])), colwidths = c(1, 3), top = FALSE) %>%
add_body_row(values = c("var_obs.", c(round(vars$vcov, 3)[2])), colwidths = c(1, 3), top = FALSE) %>%
align(i = c(23, 24), j = c(2:3), align = "center", part = "body") %>%
border_inner_h(border = fp_border_default(width = 0), part = "body") %>%
hline(i = 22) %>%
fontsize(size = 8, part = "all") %>%
set_table_properties(layout = "autofit")
RR2 %>%
set_caption("RR2: predicting political talk, Model 3 of Table 4 (excluding vignettes involving family members")
| Estimate |
| Std.Error |
|---|---|---|---|
Intercept | 4.031 | *** | 0.345 |
Gender alter (men = ref.) | -0.002 | 0.035 | |
Ethnic background alter (native Dutch = ref.) | -0.056 | 0.047 | |
Turkish | -0.046 | 0.046 | |
Tie strength (strong = ref.) | -0.195 | ** | 0.068 |
Policy (higher tax for high incomes = ref.) | -0.047 | 0.042 | |
reduce climate subsidies | 0.044 | 0.043 | |
Political distance (different = ref.) | 0.016 | 0.075 | |
Gender ego (men =ref.) | -0.284 | *** | 0.055 |
Ethnic background ego (native Dutch = ref.) | 0.045 | 0.089 | |
Turkish | -0.129 | ~ | 0.076 |
Gender similarity dyad | -0.089 | 0.070 | |
Ethnic similarity dyad | 0.059 | 0.077 | |
Age ego | -0.002 | 0.003 | |
Education ego (primary =ref.) | 0.330 | *** | 0.084 |
tertiary | 0.540 | *** | 0.085 |
Network size | -0.071 | 0.055 | |
Network gender diversity | 0.430 | ~ | 0.223 |
Network ethnic diversity | 0.326 | * | 0.148 |
Weak tie * gender similarity | 0.200 | * | 0.081 |
Weak tie * ethnic similarity | -0.028 | 0.087 | |
Weak tie * opinion similarity | 0.035 | 0.087 | |
var_resp. | 0.59 | ||
var_obs. | 0.298 | ||
***p<.001, **p<.01, *p<.05, ~p<.10 | |||
N_obs = 1,806; N_resp = 1,092 | |||
8.5 Appendix 3
Dichotomous dependent variable:
1. active political talk (original cats 4 and 5)
2. avoiding political talk (original cats 1,2 and 3)
8.5.1 Logit
# Model 0 dichotomous
M0 <- (glmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie) + as.factor(L_issue) +
as.factor(L_positie) + as.factor(L_groep) + (1 | crespnr), control = glmerControl(optimizer = c("bobyqa")),
family = binomial, data = df_tot))
# summary(M0) fsave(M0)To reach convergence we rescaled our age variable!
# scale age
df_tot$cage_s <- scale(df_tot$cage)
# hypo1 / hypo2
M1 <- glmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + female + egoM + egoT + gen_sim + ethnic_sim + cage_s + educM + educH + (1 |
crespnr), control = glmerControl(optimizer = c("bobyqa"), optCtrl = list(maxfun = 1e+05)), family = binomial,
data = df_tot)
# fsave(M1)
# hypo3
M2 <- glmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + female + egoM + egoT + gen_sim + ethnic_sim + cage_s + educM + educH + as.factor(L_relatie2) *
gen_sim + as.factor(L_relatie2) * ethnic_sim + as.factor(L_relatie2) * as.factor(L_positie2) + (1 |
crespnr), control = glmerControl(optimizer = c("bobyqa"), optCtrl = list(maxfun = 1e+05)), family = binomial,
data = df_tot)
# fsave(M2)
M3 <- glmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage_s +
educM + educH + log(netsover3) + hhi_gender + hhi_ethnic + as.factor(L_relatie2) * gen_sim + as.factor(L_relatie2) *
ethnic_sim + as.factor(L_relatie2) * as.factor(L_positie2) + (1 | crespnr), control = glmerControl(optimizer = c("bobyqa"),
optCtrl = list(maxfun = 1e+05)), family = binomial, data = df_tot)
# fsave(M3)
M4 <- glmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage_s +
educM + educH + as.factor(L_relatie2) * gen_sim + as.factor(L_relatie2) * ethnic_sim + as.factor(L_relatie2) *
as.factor(L_positie2) + log(netsover3) + hhi_gender + hhi_ethnic + gen_sim * hhi_gender + ethnic_sim *
hhi_ethnic + (1 | crespnr), control = glmerControl(optimizer = c("bobyqa"), optCtrl = list(maxfun = 1e+05)),
family = binomial, data = df_tot)
# fsave(M4)pvalue_format <- function(x) {
# p <- 2*pt(q=x, df=1000, lower.tail=FALSE)
z <- cut(x, breaks = c(-Inf, 0.001, 0.01, 0.05, 0.1, Inf), labels = c("***", "**", "*", "~", ""))
as.character(z)
}
# df_M0 <- as_tibble(summ(M0)$coeftable) %>% mutate(terms = rownames(summ(M0)$coeftable), sig =
# pvalue_format(p)) %>% select(c('terms', 'Est.', 'sig' ,'S.E.'))
df_M1 <- as_tibble(summ(M1)$coeftable) %>%
mutate(terms = rownames(summ(M1)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M2 <- as_tibble(summ(M2)$coeftable) %>%
mutate(terms = rownames(summ(M2)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M3 <- as_tibble(summ(M3)$coeftable) %>%
mutate(terms = rownames(summ(M3)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M4 <- as_tibble(summ(M4)$coeftable) %>%
mutate(terms = rownames(summ(M4)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_models <- full_join(df_M1, df_M2, by = c("terms")) %>%
full_join(y = df_M3, by = c("terms")) %>%
full_join(y = df_M4, by = c("terms"))varsm1 <- as.data.frame(VarCorr(M1))
varsm2 <- as.data.frame(VarCorr(M2))
varsm3 <- as.data.frame(VarCorr(M3))
varsm4 <- as.data.frame(VarCorr(M4))
appendix3 <- df_models %>%
flextable() %>%
add_header_row(values = c(" ", rep(c("Estimate", " ", "Std.Error"), 4)), top = FALSE) %>%
delete_rows(i = 1, part = "header") %>%
add_header_row(values = c(" ", "Model 1", "Model 2", "Model 3", "Model 4"), colwidths = c(1, 3, 3,
3, 3)) %>%
align(i = 1, align = "center", part = "header") %>%
align(j = c(3, 6, 9, 12), align = "left") %>%
padding(padding.left = 0, j = c(3, 6, 9, 12), part = "all") %>%
padding(padding.right = 0, j = c(2, 5, 8, 11), part = "all") %>%
mk_par(j = 1, value = as_paragraph(c("Intercept", "Gender alter (men = ref.) \n\n\t woman", "Ethnic background alter (native Dutch = ref.) \n\n\t Moroccan",
"\t Turkish", "Tie strength (strong = ref.) \n\n\t weak", "Policy (higher tax for high incomes = ref.) \n\n\t less refugees",
"\t reduce climate subsidies", "Political distance (different = ref.) \n\n\t similar", "Gender ego (men =ref.) \n\n\t woman",
"Ethnic background ego (native Dutch = ref.) \n\n\t Moroccan", "\t Turkish", "Gender similarity dyad",
"Ethnic similarity dyad", "Age ego", "Education ego (primary =ref.) \n\n\t secondary", "\t tertiary",
"Weak tie * gender similarity", "Weak tie * ethnic similarity", "Weak tie * opinion similarity",
"Network size", "Network gender diversity", "Network ethnic diversity", "Gender similarity * gender diversity",
"Ethnic similarity * ethnic diversity"))) %>%
valign(valign = "bottom", part = "body") %>%
width(j = 1, width = 60, unit = "mm") %>%
add_footer_lines(value = c("***p<.001, **p<.01, *p<.05, ~p<.10")) %>%
add_footer_lines(value = c("N_obs = 2,286; N_resp = 1,142")) %>%
colformat_double(digits = 3) %>%
add_body_row(values = c("var_resp.", c(round(varsm1$vcov, 3)[1], round(varsm2$vcov, 3)[1], round(varsm3$vcov,
3)[1], round(varsm4$vcov, 3)[1])), colwidths = c(1, 3, 3, 3, 3), top = FALSE) %>%
align(i = c(25), j = c(2:13), align = "center", part = "body") %>%
border_inner_h(border = fp_border_default(width = 0), part = "body") %>%
hline(i = 24) %>%
fontsize(size = 8, part = "all") %>%
set_table_properties(layout = "autofit")
appendix3 %>%
set_caption("Appendix 3: predicting actively engaging in political talk")
# fsave(appendix3)
| Model 1 | Model 2 | Model 3 | Model 4 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate |
| Std.Error | Estimate |
| Std.Error | Estimate |
| Std.Error | Estimate |
| Std.Error |
Intercept | 6.415 | *** | 0.866 | 6.825 | *** | 0.906 | 6.261 | * | 2.506 | 6.546 | * | 2.576 |
Gender alter (men = ref.) | 0.198 | 0.257 | 0.220 | 0.259 | 0.216 | 0.259 | 0.212 | 0.262 | ||||
Ethnic background alter (native Dutch = ref.) | -0.613 | ~ | 0.345 | -0.615 | ~ | 0.349 | -0.606 | ~ | 0.347 | -0.853 | * | 0.385 |
Turkish | -0.452 | 0.341 | -0.432 | 0.343 | -0.432 | 0.341 | -0.672 | ~ | 0.376 | |||
Tie strength (strong = ref.) | -0.591 | * | 0.258 | -1.344 | ** | 0.432 | -1.357 | ** | 0.431 | -1.331 | ** | 0.432 |
Policy (higher tax for high incomes = ref.) | -0.429 | 0.304 | -0.482 | 0.309 | -0.492 | 0.307 | -0.503 | 0.309 | ||||
reduce climate subsidies | -0.202 | 0.303 | -0.180 | 0.307 | -0.197 | 0.306 | -0.223 | 0.308 | ||||
Political distance (different = ref.) | 1.167 | *** | 0.294 | 0.638 | 0.458 | 0.611 | 0.456 | 0.633 | 0.460 | |||
Gender ego (men =ref.) | -0.870 | * | 0.403 | -0.911 | * | 0.407 | -0.947 | * | 0.415 | -0.968 | * | 0.417 |
Ethnic background ego (native Dutch = ref.) | 0.505 | 0.591 | 0.465 | 0.598 | 0.032 | 0.672 | -0.014 | 0.680 | ||||
Turkish | 0.182 | 0.474 | 0.186 | 0.477 | -0.171 | 0.551 | -0.196 | 0.556 | ||||
Gender similarity dyad | 0.201 | 0.257 | -0.524 | 0.419 | -0.507 | 0.416 | -0.307 | 0.799 | ||||
Ethnic similarity dyad | 0.430 | 0.310 | 0.683 | 0.499 | 0.679 | 0.495 | 0.003 | 0.638 | ||||
Age ego | 0.044 | 0.206 | 0.045 | 0.208 | 0.057 | 0.211 | 0.065 | 0.212 | ||||
Education ego (primary =ref.) | 1.232 | ~ | 0.663 | 1.258 | ~ | 0.672 | 1.327 | ~ | 0.690 | 1.350 | ~ | 0.698 |
tertiary | 1.662 | * | 0.682 | 1.707 | * | 0.691 | 1.843 | ** | 0.713 | 1.854 | * | 0.720 |
Weak tie * gender similarity | 1.203 | * | 0.522 | 1.181 | * | 0.520 | 1.148 | * | 0.522 | |||
Weak tie * ethnic similarity | -0.349 | 0.600 | -0.337 | 0.596 | -0.416 | 0.604 | ||||||
Weak tie * opinion similarity | 0.905 | 0.584 | 0.932 | 0.582 | 0.910 | 0.584 | ||||||
Network size | -0.042 | 0.410 | -0.037 | 0.413 | ||||||||
Network gender diversity | 0.818 | 1.596 | 1.044 | 1.820 | ||||||||
Network ethnic diversity | 1.581 | 1.106 | 0.982 | 1.169 | ||||||||
Gender similarity * gender diversity | -0.477 | 1.723 | ||||||||||
Ethnic similarity * ethnic diversity | 2.260 | ~ | 1.351 | |||||||||
R^2_resp. | 106.696 | 105.378 | 101.221 | 102.285 | ||||||||
***p<.001, **p<.01, *p<.05, ~p<.10 | ||||||||||||
N_obs = 2,286; N_resp = 1,142 | ||||||||||||
8.5.2 AME weak/strong ties
# mean value in data
mean(df_tot$Y_L > 3)
# check predicted values
mean(lme4:::predict.merMod(M1, type = "response")) #include all random effects
# check predicted values
mean(lme4:::predict.merMod(M1, type = "response", re.form = NA)) #not including random effects
# a huge difference, this already indicates that most of our variance is at the respondent level.
# as.data.frame(ranef(fm01ML))
mean(lme4:::predict.merMod(M1, type = "response", random.only = TRUE))
# this indeed gives indication that we have important random effects.
# define the new datasets (depends of course on the AME you are interested in. simply use the
# numerical approach for everything) we have a categorical variable.
# define datasets to avoid annoying factor behavior in predicting scores, make strong/weak ties a
# numeric variable
df_tot$strong <- as.numeric(df_tot$L_relatie2 == "strong")
dfplus <- dfmin <- df_tot
# add the increase/decrease to the variable
dfplus$strong <- 1
dfmin$strong <- 0
# re-estimate model with numeric variable. hypo1 / hypo2
M1 <- glmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + strong + as.factor(L_issue) + as.factor(L_positie2) +
female + egoM + egoT + gen_sim + ethnic_sim + cage_s + educM + educH + (1 | crespnr), control = glmerControl(optimizer = c("bobyqa"),
optCtrl = list(maxfun = 1e+05)), family = binomial, data = df_tot)
# quick check: yes, same results summary(M1)
p1 <- lme4:::predict.merMod(M1, type = "response", newdata = dfplus)
p0 <- lme4:::predict.merMod(M1, type = "response", newdata = dfmin)
ame <- mean(p1 - p0)
ame #0.0288037
# define function
mySumm <- function(fit) {
p1 <- (lme4:::predict.merMod(fit, type = "response", newdata = dfplus))
p0 <- (lme4:::predict.merMod(fit, type = "response", newdata = dfmin))
am <- p1 - p0
mean(am)
}
# run bootstrapping for SE given the very large random effects at the individual-level I do not
# want to resample these. therefore
library(parallel)
par_cores <- detectCores() - 1 #don't understand why I only see 50% of CPU usage (16 cores, 22 logical processors)
par_cluster <- makeCluster(rep("localhost", par_cores), outfile = "log.txt")
clusterEvalQ(par_cluster, library("lme4"))
clusterExport(par_cluster, varlist = c("df_tot", "M1", "dfplus", "dfmin", "mySumm"))
# note paralles 'multicore' does not seem to work, so have set up a snow cluster.
bb <- bootMer(M1, mySumm, nsim = 1000, , use.u = TRUE, parallel = "snow", ncpus = par_cores, cl = par_cluster,
verbose = TRUE, .progress = "txt")
bb
# fsave(bb)
stopCluster(cl = par_cluster)#>
#> PARAMETRIC BOOTSTRAP
#>
#>
#> Call:
#> bootMer(x = M1, FUN = mySumm, nsim = 1000, use.u = TRUE, verbose = TRUE,
#> .progress = "txt", parallel = "snow", ncpus = par_cores,
#> cl = par_cluster)
#>
#>
#> Bootstrap Statistics :
#> original bias std. error
#> t1* 0.0288037 -0.00165424 0.012534128.5.3 LPM
# Model 0 dichotomous
M0 <- (lmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie) + as.factor(L_issue) +
as.factor(L_positie) + as.factor(L_groep) + (1 | crespnr), data = df_tot))
# summary(M0)# scale age
df_tot$cage_s <- scale(df_tot$cage)
# hypo1 / hypo2
M1 <- lmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + female + egoM + egoT + gen_sim + ethnic_sim + cage_s + educM + educH + (1 |
crespnr), data = df_tot)
# hypo3
M2 <- lmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + female + egoM + egoT + gen_sim + ethnic_sim + cage_s + educM + educH + as.factor(L_relatie2) *
gen_sim + as.factor(L_relatie2) * ethnic_sim + as.factor(L_relatie2) * as.factor(L_positie2) + (1 |
crespnr), data = df_tot)
M3 <- lmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage_s +
educM + educH + log(netsover3) + hhi_gender + hhi_ethnic + as.factor(L_relatie2) * gen_sim + as.factor(L_relatie2) *
ethnic_sim + as.factor(L_relatie2) * as.factor(L_positie2) + (1 | crespnr), data = df_tot)
M4 <- lmer((Y_L > 3) ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage_s +
educM + educH + as.factor(L_relatie2) * gen_sim + as.factor(L_relatie2) * ethnic_sim + as.factor(L_relatie2) *
as.factor(L_positie2) + log(netsover3) + hhi_gender + hhi_ethnic + gen_sim * hhi_gender + ethnic_sim *
hhi_ethnic + (1 | crespnr), data = df_tot)pvalue_format <- function(x) {
# p <- 2*pt(q=x, df=1000, lower.tail=FALSE)
z <- cut(x, breaks = c(-Inf, 0.001, 0.01, 0.05, 0.1, Inf), labels = c("***", "**", "*", "~", ""))
as.character(z)
}
# df_M0 <- as_tibble(summ(M0)$coeftable) %>% mutate(terms = rownames(summ(M0)$coeftable), sig =
# pvalue_format(p)) %>% select(c('terms', 'Est.', 'sig' ,'S.E.'))
df_M1 <- as_tibble(summ(M1)$coeftable) %>%
mutate(terms = rownames(summ(M1)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M2 <- as_tibble(summ(M2)$coeftable) %>%
mutate(terms = rownames(summ(M2)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M3 <- as_tibble(summ(M3)$coeftable) %>%
mutate(terms = rownames(summ(M3)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M4 <- as_tibble(summ(M4)$coeftable) %>%
mutate(terms = rownames(summ(M4)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_models <- full_join(df_M1, df_M2, by = c("terms")) %>%
full_join(y = df_M3, by = c("terms")) %>%
full_join(y = df_M4, by = c("terms"))varsm1 <- as.data.frame(VarCorr(M1))
varsm2 <- as.data.frame(VarCorr(M2))
varsm3 <- as.data.frame(VarCorr(M3))
varsm4 <- as.data.frame(VarCorr(M4))
appendix3_lpm <- df_models %>%
flextable() %>%
add_header_row(values = c(" ", rep(c("Estimate", " ", "Std.Error"), 4)), top = FALSE) %>%
delete_rows(i = 1, part = "header") %>%
add_header_row(values = c(" ", "Model 1", "Model 2", "Model 3", "Model 4"), colwidths = c(1, 3, 3,
3, 3)) %>%
align(i = 1, align = "center", part = "header") %>%
align(j = c(3, 6, 9, 12), align = "left") %>%
padding(padding.left = 0, j = c(3, 6, 9, 12), part = "all") %>%
padding(padding.right = 0, j = c(2, 5, 8, 11), part = "all") %>%
mk_par(j = 1, value = as_paragraph(c("Intercept", "Gender alter (men = ref.) \n\n\t woman", "Ethnic background alter (native Dutch = ref.) \n\n\t Moroccan",
"\t Turkish", "Tie strength (strong = ref.) \n\n\t weak", "Policy (higher tax for high incomes = ref.) \n\n\t less refugees",
"\t reduce climate subsidies", "Political distance (different = ref.) \n\n\t similar", "Gender ego (men =ref.) \n\n\t woman",
"Ethnic background ego (native Dutch = ref.) \n\n\t Moroccan", "\t Turkish", "Gender similarity dyad",
"Ethnic similarity dyad", "Age ego", "Education ego (primary =ref.) \n\n\t secondary", "\t tertiary",
"Weak tie * gender similarity", "Weak tie * ethnic similarity", "Weak tie * opinion similarity",
"Network size", "Network gender diversity", "Network ethnic diversity", "Gender similarity * gender diversity",
"Ethnic similarity * ethnic diversity"))) %>%
valign(valign = "bottom", part = "body") %>%
width(j = 1, width = 60, unit = "mm") %>%
add_footer_lines(value = c("***p<.001, **p<.01, *p<.05, ~p<.10")) %>%
add_footer_lines(value = c("N_obs = 2,286; N_resp = 1,142")) %>%
colformat_double(digits = 3) %>%
add_body_row(values = c("R^2_resp.", c(round(varsm1$vcov, 3)[1], round(varsm2$vcov, 3)[1], round(varsm3$vcov,
3)[1], round(varsm4$vcov, 3)[1])), colwidths = c(1, 3, 3, 3, 3), top = FALSE) %>%
align(i = c(25), j = c(2:13), align = "center", part = "body") %>%
add_body_row(values = c("R^2_obs.", c(round(varsm1$vcov, 3)[2], round(varsm2$vcov, 3)[2], round(varsm3$vcov,
3)[2], round(varsm4$vcov, 3)[2])), colwidths = c(1, 3, 3, 3, 3), top = FALSE) %>%
align(i = c(26), j = c(2:13), align = "center", part = "body") %>%
border_inner_h(border = fp_border_default(width = 0), part = "body") %>%
hline(i = 24) %>%
fontsize(size = 8, part = "all") %>%
set_table_properties(layout = "autofit")
appendix3_lpm
# not shown in manuscript fsave(appendix3_lpm)
| Model 1 | Model 2 | Model 3 | Model 4 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate |
| Std.Error | Estimate |
| Std.Error | Estimate |
| Std.Error | Estimate |
| Std.Error |
Intercept | 0.626 | *** | 0.043 | 0.661 | *** | 0.044 | 0.645 | *** | 0.140 | 0.645 | *** | 0.143 |
Gender alter (men = ref.) | 0.009 | 0.015 | 0.010 | 0.015 | 0.010 | 0.015 | 0.010 | 0.015 | ||||
Ethnic background alter (native Dutch = ref.) | -0.027 | 0.021 | -0.028 | 0.021 | -0.028 | 0.020 | -0.039 | ~ | 0.022 | |||
Turkish | -0.028 | 0.020 | -0.025 | 0.020 | -0.025 | 0.020 | -0.036 | ~ | 0.022 | |||
Tie strength (strong = ref.) | -0.030 | ~ | 0.016 | -0.093 | *** | 0.026 | -0.093 | *** | 0.026 | -0.092 | *** | 0.026 |
Policy (higher tax for high incomes = ref.) | -0.028 | 0.019 | -0.031 | 0.019 | -0.032 | ~ | 0.019 | -0.032 | ~ | 0.019 | ||
reduce climate subsidies | -0.001 | 0.019 | 0.001 | 0.019 | -0.001 | 0.019 | -0.001 | 0.019 | ||||
Political distance (different = ref.) | 0.049 | ** | 0.016 | 0.005 | 0.025 | 0.004 | 0.025 | 0.003 | 0.025 | |||
Gender ego (men =ref.) | -0.085 | *** | 0.024 | -0.085 | *** | 0.024 | -0.086 | *** | 0.024 | -0.087 | *** | 0.024 |
Ethnic background ego (native Dutch = ref.) | 0.064 | ~ | 0.035 | 0.060 | ~ | 0.035 | 0.015 | 0.039 | 0.014 | 0.039 | ||
Turkish | 0.026 | 0.028 | 0.025 | 0.028 | -0.015 | 0.033 | -0.016 | 0.033 | ||||
Gender similarity dyad | 0.013 | 0.015 | -0.030 | 0.024 | -0.028 | 0.024 | 0.009 | 0.049 | ||||
Ethnic similarity dyad | 0.026 | 0.018 | 0.030 | 0.027 | 0.031 | 0.027 | -0.003 | 0.037 | ||||
Age ego | 0.005 | 0.012 | 0.005 | 0.012 | 0.005 | 0.012 | 0.005 | 0.012 | ||||
Education ego (primary =ref.) | 0.120 | ** | 0.037 | 0.120 | ** | 0.036 | 0.122 | *** | 0.036 | 0.123 | *** | 0.036 |
tertiary | 0.174 | *** | 0.037 | 0.172 | *** | 0.037 | 0.181 | *** | 0.037 | 0.180 | *** | 0.037 |
Weak tie * gender similarity | 0.076 | * | 0.031 | 0.074 | * | 0.031 | 0.073 | * | 0.031 | |||
Weak tie * ethnic similarity | -0.001 | 0.033 | -0.001 | 0.033 | -0.003 | 0.033 | ||||||
Weak tie * opinion similarity | 0.077 | * | 0.033 | 0.078 | * | 0.033 | 0.078 | * | 0.033 | |||
Network size | -0.010 | 0.024 | -0.010 | 0.024 | ||||||||
Network gender diversity | 0.105 | 0.095 | 0.151 | 0.109 | ||||||||
Network ethnic diversity | 0.160 | * | 0.064 | 0.128 | ~ | 0.068 | ||||||
Gender similarity * gender diversity | -0.089 | 0.108 | ||||||||||
Ethnic similarity * ethnic diversity | 0.102 | 0.077 | ||||||||||
R^2_resp. | 0.115 | 0.114 | 0.113 | 0.113 | ||||||||
R^2_obs. | 0.084 | 0.084 | 0.084 | 0.084 | ||||||||
***p<.001, **p<.01, *p<.05, ~p<.10 | ||||||||||||
N_obs = 2,286; N_resp = 1,142 | ||||||||||||
8.6 Appendix 4
We also performed ethnic sub-group analysis. Mostly to check whether dyadic ethnic dissimilarity (i.e. outgroup) and network ethnic diversity has the same impact across the main ethnic groups in our sample.
M4b_tot <- lmer(Y_L ~ as.factor(L_gender) + as.factor(outgroup) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + female + egoM + egoT + gen_sim + cage + educM + educH + as.factor(L_relatie2) *
gen_sim + as.factor(L_relatie2) * as.factor(outgroup) + as.factor(L_relatie2) * as.factor(L_positie2) +
log(netsover3) + hhi_gender + hhi_ethnic + gen_sim * hhi_gender + as.factor(outgroup) * hhi_ethnic +
(1 | crespnr), data = df_tot)
M4b_NL <- lmer(Y_L ~ as.factor(L_gender) + as.factor(outgroup) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(outgroup) + female + gen_sim + cage + educM + educH + as.factor(L_relatie2) *
gen_sim + as.factor(L_relatie2) * as.factor(outgroup) + as.factor(L_relatie2) * as.factor(L_positie2) +
log(netsover3) + hhi_gender + hhi_ethnic + gen_sim * hhi_gender + as.factor(outgroup) * hhi_ethnic +
(1 | crespnr), data = df_tot[df_tot$egoNL == 1, ])
M4b_M <- lmer(Y_L ~ as.factor(L_gender) + as.factor(outgroup) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(outgroup) + female + gen_sim + cage + educM + educH + as.factor(L_relatie2) *
gen_sim + as.factor(L_relatie2) * as.factor(outgroup) + as.factor(L_relatie2) * as.factor(L_positie2) +
log(netsover3) + hhi_gender + hhi_ethnic + gen_sim * hhi_gender + as.factor(outgroup) * hhi_ethnic +
(1 | crespnr), data = df_tot[df_tot$egoM == 1, ])
M4b_T <- lmer(Y_L ~ as.factor(L_gender) + as.factor(outgroup) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(outgroup) + female + gen_sim + cage + educM + educH + as.factor(L_relatie2) *
gen_sim + as.factor(L_relatie2) * as.factor(outgroup) + as.factor(L_relatie2) * as.factor(L_positie2) +
log(netsover3) + hhi_gender + hhi_ethnic + gen_sim * hhi_gender + as.factor(outgroup) * hhi_ethnic +
(1 | crespnr), data = df_tot[df_tot$egoT == 1, ])pvalue_format <- function(x) {
# p <- 2*pt(q=x, df=1000, lower.tail=FALSE)
z <- cut(x, breaks = c(-Inf, 0.001, 0.01, 0.05, 0.1, Inf), labels = c("***", "**", "*", "~", ""))
as.character(z)
}
df_M4b <- as_tibble(summ(M4b_tot)$coeftable) %>%
mutate(terms = rownames(summ(M4b_tot)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M4b_NL <- as_tibble(summ(M4b_NL)$coeftable) %>%
mutate(terms = rownames(summ(M4b_NL)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M4b_M <- as_tibble(summ(M4b_M)$coeftable) %>%
mutate(terms = rownames(summ(M4b_M)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
df_M4b_T <- as_tibble(summ(M4b_T)$coeftable) %>%
mutate(terms = rownames(summ(M4b_T)$coeftable), sig = pvalue_format(p)) %>%
select(c("terms", "Est.", "sig", "S.E."))
dfM4b <- full_join(df_M4b, df_M4b_NL, by = c("terms")) %>%
full_join(y = df_M4b_M, by = c("terms")) %>%
full_join(y = df_M4b_T, by = c("terms"))varsm1 <- as.data.frame(VarCorr(M4b_tot))
varsm2 <- as.data.frame(VarCorr(M4b_NL))
varsm3 <- as.data.frame(VarCorr(M4b_M))
varsm4 <- as.data.frame(VarCorr(M4b_T))appendix4 <- dfM4b %>%
flextable() %>%
add_header_row(values = c(" ", rep(c("Estimate", " ", "Std.Error"), 4)), top = FALSE) %>%
delete_rows(i = 1, part = "header") %>%
add_header_row(values = c(" ", "Model 4b \n(all)", "Model 4b \n(native Dutch)", "Model 4b \n(Moroccan Dutch)",
"Model 4b \n(Turkish Dutch)"), colwidths = c(1, 3, 3, 3, 3)) %>%
align(i = 1, align = "center", part = "header") %>%
align(j = c(3, 6, 9, 12), align = "left") %>%
padding(padding.left = 0, j = c(3, 6, 9, 12), part = "all") %>%
padding(padding.right = 0, j = c(2, 5, 8, 11), part = "all") %>%
mk_par(j = 1, value = as_paragraph(c("Intercept", "Gender alter (Men = ref.) \n\n\t woman", "Ethnic background alter (ingroup = ref.) \n\n\t outgroup",
"Tie strength (strong = ref.) \n\n\t weak", "Policy (higher tax for high incomes = ref.) \n\n\t less refugees",
"\t reduce climate subsidies", "Political distance (different = ref.): about the same", "Gender ego (men =ref.) \n\n\t woman",
"Ethnic background ego (native Dutch = ref.) \n\n\t Moroccan", "\t Turkish", "Dyad: gender similarity",
"Age ego", "Education ego (low =ref.) \n\n\t medium", "\t high", "Network size", "Network gender diversity",
"Network ethnic diversity", "Weak tie * gender similarity", "Weak tie * ethnic similarity", "Weak tie * opinion similarity",
"Gender similarity * gender diversity", "outgroup * ethnic diversity"))) %>%
valign(valign = "bottom", part = "body") %>%
width(j = 1, width = 60, unit = "mm") %>%
add_footer_lines(value = c("***p<.001, **p<.01, *p<.05, ~p<.10")) %>%
colformat_double(digits = 3) %>%
add_body_row(values = c("R^2_resp.", c(round(varsm1$vcov, 3)[1], round(varsm2$vcov, 3)[1], round(varsm3$vcov,
3)[1], round(varsm4$vcov, 3)[1])), colwidths = c(1, 3, 3, 3, 3), top = FALSE) %>%
align(i = c(23), j = c(2:13), align = "center", part = "body") %>%
add_body_row(values = c("R^2_obs.", c(round(varsm1$vcov, 3)[2], round(varsm2$vcov, 3)[2], round(varsm3$vcov,
3)[2], round(varsm4$vcov, 3)[2])), colwidths = c(1, 3, 3, 3, 3), top = FALSE) %>%
align(i = c(24), j = c(2:13), align = "center", part = "body") %>%
border_inner_h(border = fp_border_default(width = 0), part = "body") %>%
hline(i = 22) %>%
fontsize(size = 8, part = "all") %>%
set_table_properties(layout = "autofit")
appendix4
# fsave(appendix4)
| Model 4b | Model 4b | Model 4b | Model 4b | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate |
| Std.Error | Estimate |
| Std.Error | Estimate |
| Std.Error | Estimate |
| Std.Error |
Intercept | 3.912 | *** | 0.329 | 4.058 | *** | 0.424 | 4.169 | *** | 1.000 | 3.217 | *** | 0.619 |
Gender alter (Men = ref.) | -0.003 | 0.030 | -0.002 | 0.038 | -0.036 | 0.090 | 0.040 | 0.061 | ||||
Ethnic background alter (ingroup = ref.) | -0.027 | 0.062 | -0.046 | 0.071 | -0.030 | 0.366 | 0.127 | 0.172 | ||||
Tie strength (strong = ref.) | -0.191 | ** | 0.064 | -0.262 | ** | 0.079 | -0.024 | 0.175 | -0.104 | 0.147 | ||
Policy (higher tax for high incomes = ref.) | -0.038 | 0.036 | -0.032 | 0.046 | -0.129 | 0.101 | -0.009 | 0.076 | ||||
reduce climate subsidies | 0.013 | 0.036 | 0.015 | 0.044 | -0.084 | 0.106 | 0.050 | 0.078 | ||||
Political distance (different = ref.): about the same | -0.055 | 0.049 | -0.042 | 0.062 | 0.090 | 0.152 | -0.140 | 0.101 | ||||
Gender ego (men =ref.) | -0.252 | *** | 0.052 | -0.332 | *** | 0.063 | 0.052 | 0.184 | -0.240 | * | 0.107 | |
Ethnic background ego (native Dutch = ref.) | -0.013 | 0.085 | ||||||||||
Turkish | -0.140 | ~ | 0.072 | |||||||||
Dyad: gender similarity | -0.068 | 0.095 | -0.104 | 0.120 | 0.195 | 0.375 | -0.072 | 0.179 | ||||
Age ego | -0.001 | 0.003 | 0.001 | 0.004 | 0.009 | 0.009 | -0.008 | 0.006 | ||||
Education ego (low =ref.) | 0.309 | *** | 0.080 | 0.319 | ** | 0.107 | -0.021 | 0.209 | 0.486 | ** | 0.159 | |
high | 0.530 | *** | 0.081 | 0.483 | *** | 0.109 | 0.359 | 0.228 | 0.720 | *** | 0.155 | |
Network size | -0.046 | 0.052 | -0.048 | 0.066 | -0.199 | 0.166 | 0.051 | 0.097 | ||||
Network gender diversity | 0.203 | 0.233 | -0.059 | 0.284 | 0.699 | 0.905 | 0.677 | 0.453 | ||||
Network ethnic diversity | 0.459 | ** | 0.166 | 0.731 | *** | 0.212 | 0.673 | 0.744 | -0.091 | 0.358 | ||
Weak tie * gender similarity | 0.159 | ** | 0.060 | 0.185 | * | 0.074 | 0.062 | 0.178 | 0.155 | 0.127 | ||
Weak tie * ethnic similarity | 0.007 | 0.064 | 0.032 | 0.080 | 0.046 | 0.187 | -0.074 | 0.141 | ||||
Weak tie * opinion similarity | 0.119 | ~ | 0.064 | 0.102 | 0.081 | -0.069 | 0.193 | 0.176 | 0.132 | |||
Gender similarity * gender diversity | 0.065 | 0.208 | 0.073 | 0.260 | -0.111 | 0.846 | 0.036 | 0.398 | ||||
outgroup * ethnic diversity | -0.133 | 0.134 | -0.246 | 0.201 | -0.167 | 0.664 | -0.219 | 0.311 | ||||
R^2_resp. | 0.601 | 0.529 | 0.915 | 0.586 | ||||||||
R^2_obs. | 0.294 | 0.284 | 0.329 | 0.31 | ||||||||
***p<.001, **p<.01, *p<.05, ~p<.10 | ||||||||||||
8.7 Appendix 5 / miscellaneous
This is not shown in manuscript but we refer to this replication website.
8.7.1 solely size without diversity
M3_robustness1 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage +
educM + educH + log(netsover3) + (1 | crespnr), data = df_tot)
df <- round(as.data.frame(summary(M3_robustness1)$coefficients), 3) %>%
rownames_to_column(" ")
flextable(df)
| Estimate | Std. Error | t value |
|---|---|---|---|
(Intercept) | 3.653 | 0.319 | 11.447 |
as.factor(L_gender)2 | -0.001 | 0.030 | -0.050 |
as.factor(L_groep)1 | -0.059 | 0.040 | -1.491 |
as.factor(L_groep)3 | -0.048 | 0.039 | -1.251 |
as.factor(L_relatie2)weak | -0.069 | 0.030 | -2.302 |
as.factor(L_issue)2 | -0.032 | 0.036 | -0.872 |
as.factor(L_issue)3 | 0.013 | 0.036 | 0.372 |
as.factor(L_positie2)same | 0.016 | 0.032 | 0.505 |
female | -0.245 | 0.052 | -4.721 |
egoM | 0.096 | 0.076 | 1.256 |
egoT | -0.045 | 0.063 | -0.710 |
gen_sim | 0.045 | 0.030 | 1.519 |
ethnic_sim | 0.028 | 0.035 | 0.797 |
cage | 0.000 | 0.003 | -0.127 |
educM | 0.304 | 0.080 | 3.780 |
educH | 0.516 | 0.081 | 6.328 |
log(netsover3) | 0.012 | 0.047 | 0.256 |
No, size no effect.
8.7.2 diversity modelled differently
Check if number of different dyads in network should not be modeled differently
M3_robustness2 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage +
educM + educH + log(netsover3):hhi_gender + log(netsover3):hhi_ethnic + (1 | crespnr), data = df_tot)
df <- round(as.data.frame(summary(M3_robustness2)$coefficients), 3) %>%
rownames_to_column(" ")
flextable(df)
| Estimate | Std. Error | t value |
|---|---|---|---|
(Intercept) | 3.613 | 0.141 | 25.582 |
as.factor(L_gender)2 | -0.002 | 0.030 | -0.053 |
as.factor(L_groep)1 | -0.059 | 0.040 | -1.495 |
as.factor(L_groep)3 | -0.049 | 0.039 | -1.269 |
as.factor(L_relatie2)weak | -0.071 | 0.030 | -2.347 |
as.factor(L_issue)2 | -0.033 | 0.036 | -0.898 |
as.factor(L_issue)3 | 0.010 | 0.036 | 0.288 |
as.factor(L_positie2)same | 0.016 | 0.032 | 0.515 |
female | -0.240 | 0.052 | -4.601 |
egoM | -0.003 | 0.086 | -0.039 |
egoT | -0.128 | 0.072 | -1.784 |
gen_sim | 0.046 | 0.030 | 1.536 |
ethnic_sim | 0.029 | 0.035 | 0.823 |
cage | 0.000 | 0.003 | -0.092 |
educM | 0.310 | 0.080 | 3.864 |
educH | 0.536 | 0.082 | 6.567 |
log(netsover3):hhi_gender | 0.010 | 0.030 | 0.345 |
log(netsover3):hhi_ethnic | 0.056 | 0.022 | 2.470 |
No, just as main analyses, it is just ethnic diversity.
8.7.3 adding educational diversity
M3_robustness3 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) + as.factor(L_issue) +
as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim + ethnic_sim + cage +
educM + educH + log(netsover3) + hhi_gender + hhi_ethnic + hhi_educ + (1 | crespnr), data = df_tot)
df <- round(as.data.frame(summary(M3_robustness3)$coefficients), 3) %>%
rownames_to_column(" ")
flextable(df)
| Estimate | Std. Error | t value |
|---|---|---|---|
(Intercept) | 3.919 | 0.359 | 10.912 |
as.factor(L_gender)2 | -0.002 | 0.031 | -0.054 |
as.factor(L_groep)1 | -0.052 | 0.041 | -1.257 |
as.factor(L_groep)3 | -0.024 | 0.041 | -0.586 |
as.factor(L_relatie2)weak | -0.068 | 0.031 | -2.167 |
as.factor(L_issue)2 | -0.033 | 0.037 | -0.870 |
as.factor(L_issue)3 | 0.005 | 0.037 | 0.124 |
as.factor(L_positie2)same | 0.013 | 0.033 | 0.401 |
female | -0.234 | 0.055 | -4.284 |
egoM | -0.027 | 0.088 | -0.306 |
egoT | -0.168 | 0.078 | -2.164 |
gen_sim | 0.047 | 0.031 | 1.515 |
ethnic_sim | 0.046 | 0.037 | 1.240 |
cage | 0.000 | 0.003 | 0.080 |
educM | 0.263 | 0.083 | 3.172 |
educH | 0.474 | 0.085 | 5.570 |
log(netsover3) | -0.043 | 0.062 | -0.703 |
hhi_gender | 0.166 | 0.223 | 0.744 |
hhi_ethnic | 0.388 | 0.149 | 2.609 |
hhi_educ | -0.115 | 0.133 | -0.865 |
No educational diversity no effect.
8.7.4 NSUM size
8.7.4.1 In empty model
M3_robustness_size1 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) +
as.factor(L_issue) + as.factor(L_positie2) + as.factor(L_groep) + log(netsover3) + (1 | crespnr),
data = df_tot)
df <- round(as.data.frame(summary(M3_robustness_size1)$coefficients), 3) %>%
rownames_to_column(" ")
flextable(df)
| Estimate | Std. Error | t value |
|---|---|---|---|
(Intercept) | 3.980 | 0.289 | 13.763 |
as.factor(L_gender)2 | 0.000 | 0.030 | -0.008 |
as.factor(L_groep)1 | -0.079 | 0.036 | -2.189 |
as.factor(L_groep)3 | -0.060 | 0.036 | -1.642 |
as.factor(L_relatie2)weak | -0.069 | 0.030 | -2.287 |
as.factor(L_issue)2 | -0.029 | 0.036 | -0.808 |
as.factor(L_issue)3 | 0.016 | 0.036 | 0.452 |
as.factor(L_positie2)same | 0.019 | 0.032 | 0.612 |
log(netsover3) | 0.001 | 0.047 | 0.017 |
8.7.4.2 NSUM size in categories
This appendix is not included in the main manuscript.
# parameters that will be passed to ``stat_function``
n = sum(!is.na(df_tot$netsover3))
mean = mean(df_tot$netsover3, na.rm = T)
sd = sd(df_tot$netsover3, na.rm = T)
binwidth = 25 # passed to geom_histogram and stat_function
set.seed(1)
df_plot <- data.frame(x = df_tot$netsover3[!is.na(df_tot$netsover3)])
appendix5 <- ggplot(df_plot, aes(x = x, mean = mean, sd = sd, binwidth = binwidth, n = n)) + theme_bw() +
geom_histogram(binwidth = binwidth, colour = "white", fill = "cornflowerblue", linewidth = 0.1) +
stat_function(fun = function(x) dnorm(x, mean = mean, sd = sd) * n * binwidth, color = "darkred",
linewidth = 1) + ylab(c("count")) + xlab(c("Network size"))
# + scale_x_continuous(breaks = c(1:5), label = c('stop \nconversation', 'change \nsubject', 'only
# \nlisten', 'disclose \nown opinion', 'substantive \ndiscussion'), name = 'choice')
# #theme(axis.text.x = element_text(angle = 70, vjust = .8, hjust=.9))
appendix5
Appendix 5: Distribution of Network Size
Calculate the quantiles
quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))#> 0% 20% 40% 60% 80% 100%
#> 89.16824 281.03725 385.51150 507.76754 730.40253 2691.24182Use these quantiles in the regression
M3_robustness_size2 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) +
as.factor(L_issue) + as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim +
ethnic_sim + cage + educM + educH + (netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2]) +
(netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2] & netsover3 <= quantile(df_tot$netsover3,
probs = seq(0, 1, 0.2))[3]) + (netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3] &
netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4]) + (netsover3 > quantile(df_tot$netsover3,
probs = seq(0, 1, 0.2))[4] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[5]) +
hhi_gender + hhi_ethnic + (1 | crespnr), data = df_tot)
df <- round(as.data.frame(summary(M3_robustness_size2)$coefficients), 3) %>%
rownames_to_column(" ")
flextable(df)
| Estimate | Std. Error | t value |
|---|---|---|---|
(Intercept) | 3.519 | 0.159 | 22.128 |
as.factor(L_gender)2 | -0.001 | 0.030 | -0.049 |
as.factor(L_groep)1 | -0.059 | 0.040 | -1.495 |
as.factor(L_groep)3 | -0.049 | 0.039 | -1.254 |
as.factor(L_relatie2)weak | -0.071 | 0.030 | -2.350 |
as.factor(L_issue)2 | -0.033 | 0.036 | -0.911 |
as.factor(L_issue)3 | 0.010 | 0.036 | 0.282 |
as.factor(L_positie2)same | 0.015 | 0.032 | 0.474 |
female | -0.253 | 0.052 | -4.821 |
egoM | -0.008 | 0.086 | -0.088 |
egoT | -0.130 | 0.073 | -1.790 |
gen_sim | 0.047 | 0.030 | 1.584 |
ethnic_sim | 0.029 | 0.035 | 0.823 |
cage | 0.000 | 0.003 | -0.089 |
educM | 0.301 | 0.080 | 3.744 |
educH | 0.530 | 0.082 | 6.495 |
netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2]TRUE | 0.018 | 0.091 | 0.204 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3]TRUE | 0.144 | 0.083 | 1.733 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4]TRUE | 0.089 | 0.082 | 1.078 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[5]TRUE | 0.102 | 0.082 | 1.248 |
hhi_gender | 0.143 | 0.209 | 0.688 |
hhi_ethnic | 0.358 | 0.140 | 2.555 |
Is this consistent across ethnic groups
M3_robustness_size2 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) +
as.factor(L_issue) + as.factor(L_positie2) + as.factor(L_groep) + female + gen_sim + ethnic_sim +
cage + educM + educH + (netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2]) + (netsover3 >
quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0,
1, 0.2))[3]) + (netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3] & netsover3 <=
quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4]) + (netsover3 > quantile(df_tot$netsover3,
probs = seq(0, 1, 0.2))[4] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[5]) +
hhi_gender + hhi_ethnic + (1 | crespnr), data = df_tot[df_tot$egoNL == 1, ])
df <- round(as.data.frame(summary(M3_robustness_size2)$coefficients), 3) %>%
rownames_to_column(" ")
flextable(df)
| Estimate | Std. Error | t value |
|---|---|---|---|
(Intercept) | 3.634 | 0.190 | 19.112 |
as.factor(L_gender)2 | -0.003 | 0.038 | -0.074 |
as.factor(L_groep)1 | -0.087 | 0.045 | -1.953 |
as.factor(L_groep)3 | -0.046 | 0.046 | -1.020 |
as.factor(L_relatie2)weak | -0.116 | 0.038 | -3.074 |
as.factor(L_issue)2 | -0.025 | 0.046 | -0.540 |
as.factor(L_issue)3 | 0.012 | 0.044 | 0.277 |
as.factor(L_positie2)same | 0.013 | 0.040 | 0.315 |
female | -0.338 | 0.064 | -5.320 |
gen_sim | 0.028 | 0.038 | 0.752 |
cage | 0.001 | 0.004 | 0.330 |
educM | 0.309 | 0.107 | 2.876 |
educH | 0.478 | 0.110 | 4.350 |
netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2]TRUE | 0.030 | 0.112 | 0.268 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3]TRUE | 0.136 | 0.101 | 1.337 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4]TRUE | 0.125 | 0.099 | 1.264 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[5]TRUE | 0.039 | 0.097 | 0.398 |
hhi_gender | -0.067 | 0.252 | -0.267 |
hhi_ethnic | 0.586 | 0.165 | 3.552 |
M3_robustness_size2 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) +
as.factor(L_issue) + as.factor(L_positie2) + as.factor(L_groep) + female + gen_sim + ethnic_sim +
cage + educM + educH + (netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2]) + (netsover3 >
quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0,
1, 0.2))[3]) + (netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3] & netsover3 <=
quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4]) + (netsover3 > quantile(df_tot$netsover3,
probs = seq(0, 1, 0.2))[4] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[5]) +
hhi_gender + hhi_ethnic + (1 | crespnr), data = df_tot[df_tot$egoM == 1, ])
df <- round(as.data.frame(summary(M3_robustness_size2)$coefficients), 3) %>%
rownames_to_column(" ")
flextable(df)
| Estimate | Std. Error | t value |
|---|---|---|---|
(Intercept) | 3.147 | 0.581 | 5.418 |
as.factor(L_gender)2 | -0.047 | 0.087 | -0.541 |
as.factor(L_groep)1 | -0.305 | 0.761 | -0.400 |
as.factor(L_groep)3 | -0.127 | 0.107 | -1.179 |
as.factor(L_relatie2)weak | 0.007 | 0.084 | 0.088 |
as.factor(L_issue)2 | -0.133 | 0.099 | -1.336 |
as.factor(L_issue)3 | -0.103 | 0.106 | -0.974 |
as.factor(L_positie2)same | 0.056 | 0.091 | 0.619 |
female | 0.059 | 0.186 | 0.319 |
gen_sim | 0.193 | 0.087 | 2.217 |
ethnic_sim | 0.332 | 0.760 | 0.437 |
cage | 0.009 | 0.009 | 1.041 |
educM | -0.034 | 0.210 | -0.163 |
educH | 0.329 | 0.228 | 1.440 |
netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2]TRUE | 0.015 | 0.330 | 0.046 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3]TRUE | 0.222 | 0.261 | 0.853 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4]TRUE | 0.092 | 0.248 | 0.372 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[5]TRUE | 0.232 | 0.254 | 0.913 |
hhi_gender | 0.167 | 0.828 | 0.201 |
hhi_ethnic | 0.389 | 0.614 | 0.633 |
M3_robustness_size2 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) +
as.factor(L_issue) + as.factor(L_positie2) + as.factor(L_groep) + female + gen_sim + ethnic_sim +
cage + educM + educH + (netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2]) + (netsover3 >
quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0,
1, 0.2))[3]) + (netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3] & netsover3 <=
quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4]) + (netsover3 > quantile(df_tot$netsover3,
probs = seq(0, 1, 0.2))[4] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[5]) +
hhi_gender + hhi_ethnic + (1 | crespnr), data = df_tot[df_tot$egoT == 1, ])
df <- round(as.data.frame(summary(M3_robustness_size2)$coefficients), 3) %>%
rownames_to_column(" ")
flextable(df)
| Estimate | Std. Error | t value |
|---|---|---|---|
(Intercept) | 3.568 | 0.368 | 9.688 |
as.factor(L_gender)2 | 0.042 | 0.061 | 0.691 |
as.factor(L_groep)1 | -0.054 | 0.074 | -0.732 |
as.factor(L_groep)3 | -0.358 | 0.720 | -0.497 |
as.factor(L_relatie2)weak | -0.016 | 0.064 | -0.253 |
as.factor(L_issue)2 | -0.002 | 0.075 | -0.025 |
as.factor(L_issue)3 | 0.046 | 0.078 | 0.587 |
as.factor(L_positie2)same | -0.035 | 0.066 | -0.529 |
female | -0.242 | 0.107 | -2.251 |
gen_sim | 0.028 | 0.061 | 0.457 |
ethnic_sim | 0.333 | 0.719 | 0.464 |
cage | -0.007 | 0.006 | -1.109 |
educM | 0.467 | 0.161 | 2.912 |
educH | 0.718 | 0.156 | 4.604 |
netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2]TRUE | -0.105 | 0.179 | -0.587 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3]TRUE | 0.111 | 0.173 | 0.643 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[3] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4]TRUE | 0.042 | 0.184 | 0.230 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[4] & netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[5]TRUE | 0.089 | 0.188 | 0.475 |
hhi_gender | 0.642 | 0.403 | 1.596 |
hhi_ethnic | -0.289 | 0.291 | -0.990 |
8.7.4.3 change refs cats to quantiles 2,3 and 4.
M3_robustness_size3 <- lmer(Y_L ~ as.factor(L_gender) + as.factor(L_groep) + as.factor(L_relatie2) +
as.factor(L_issue) + as.factor(L_positie2) + as.factor(L_groep) + female + egoM + egoT + gen_sim +
ethnic_sim + cage + educM + educH + (netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2]) +
(netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[5]) + hhi_gender + hhi_ethnic + (1 |
crespnr), data = df_tot)
df <- round(as.data.frame(summary(M3_robustness_size3)$coefficients), 3) %>%
rownames_to_column(" ")
flextable(df)
| Estimate | Std. Error | t value |
|---|---|---|---|
(Intercept) | 3.633 | 0.148 | 24.536 |
as.factor(L_gender)2 | -0.002 | 0.030 | -0.051 |
as.factor(L_groep)1 | -0.059 | 0.040 | -1.492 |
as.factor(L_groep)3 | -0.049 | 0.039 | -1.256 |
as.factor(L_relatie2)weak | -0.071 | 0.030 | -2.364 |
as.factor(L_issue)2 | -0.033 | 0.036 | -0.917 |
as.factor(L_issue)3 | 0.010 | 0.036 | 0.283 |
as.factor(L_positie2)same | 0.015 | 0.032 | 0.488 |
female | -0.253 | 0.052 | -4.824 |
egoM | -0.007 | 0.085 | -0.078 |
egoT | -0.127 | 0.072 | -1.756 |
gen_sim | 0.048 | 0.030 | 1.599 |
ethnic_sim | 0.030 | 0.035 | 0.838 |
cage | 0.000 | 0.003 | -0.067 |
educM | 0.303 | 0.080 | 3.766 |
educH | 0.532 | 0.081 | 6.528 |
netsover3 <= quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[2]TRUE | -0.096 | 0.072 | -1.318 |
netsover3 > quantile(df_tot$netsover3, probs = seq(0, 1, 0.2))[5]TRUE | -0.111 | 0.067 | -1.643 |
hhi_gender | 0.130 | 0.207 | 0.627 |
hhi_ethnic | 0.355 | 0.140 | 2.545 |
Copyright © 2024- Bas Hofstra, Thijmen Jeroense, Jochem Tolsma